
프로세스와 스레드
멀티 태스킹 vs 멀티 프로세싱
- 멀티 태스킹
- CPU 코어가 프로세스 내 쓰레드를 스케줄링(시분할)으로 처리
- 하나의 CPU 코어가 동시에 여러 작업을 수행하는 능력
- 멀티 프로세싱
- 컴퓨터 시스템에서 둘 이상 CPU 코어를 사용하여 여러 작업을 동시에 처리하는 기술
프로세스와 스레드
- 프로그램
- 실행 전까지는 단순한 파일
- 프로그램 실행 시 프로세스 생성 → 프로그램 실행
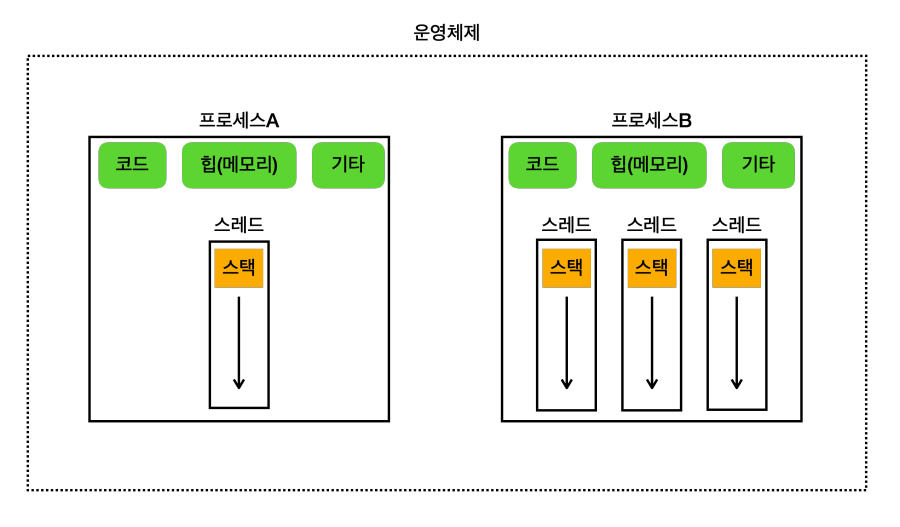
- 프로세스
- 실행중인 프로그램
- 하나 이상의 스레드를 반드시 포함한다.
- 각 프로세스는 서로 독립적이다.
- 스레드: 프로세스 내 실행되는 작업의 단위
- 단일 스레드
- 멀티 스레드
- e.g. 워드 프로그램
- 스레드1: 문서 편집
- 스레드2: 자동 저장
- 스레드3: 맞춤법 검사
- e.g. 워드 프로그램
- 같은 프로세스의 코드 섹션, 데이터 섹션, 힙(메모리)은 프로세스 안의 모든 스레드가 공유한다.
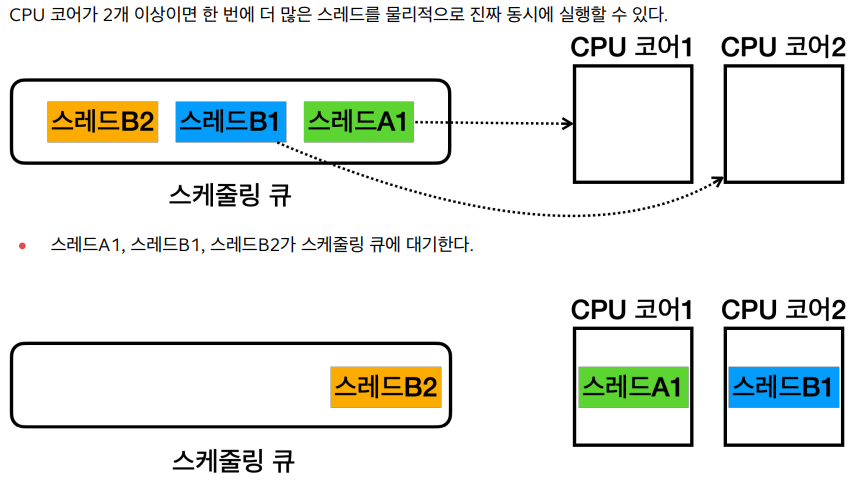
- 스케줄링
- CPU에 어떤 프로그램이 얼마만큼 실행될지는 운영체제가 결정
- CPU를 최대한 활용할 수 있는 다양한 우선순위와 최적화 기법을 사용
- 단일 코어 스케줄링
- 멀티 코어 스케줄링

컨텍스트 스위칭(Context Switching)
- 문맥교환
- 작업하던 스레드에서 다른 스레드로 CPU 할당
- 약간의 비용 발생
- 스레드가 하는 작업 크게 두 가지로 분류
- CPU-바운드 작업
- CPU의 연산 능력을 많이 요구하는 작업
- 이상적인 스레드 수: CPU 코어 수 + 1개
- I/O-바운드 작업
- 디스크, 네트워크, 파일 시스템 등과 같은 입출력(I/O) 작업을 많이 요구하는 작업
- I/O 작업이 완료될 때까지 대기 시간이 많이 발생. CPU는 상대적으로 유휴(대기) 상태
- 스레드가 CPU를 사용하지 않고 I/O 작업이 완료될 때 까지 대기
- 이상적인 스레드 수: CPU 코어 수 보다 많은 스레드를 생성, CPU를 최대한 사용할 수 있는 숫자까지 스레드 생성
- CPU-바운드 작업
스레드
extends Thread
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
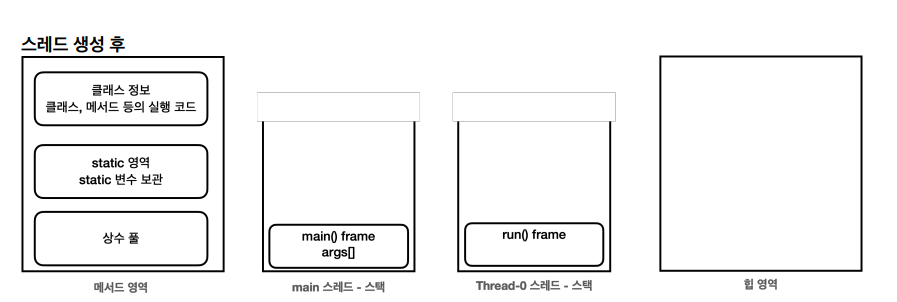
public class HelloThreadMain {
public static void main(String[] args) {
// Thread.currentThread(): 현재 이 코드를 실행하는 스레드
System.out.println(Thread.currentThread().getName() + ": main() start");
HelloThread helloThread = new HelloThread();
System.out.println(Thread.currentThread().getName() + ": start() 호출 전");
helloThread.start(); // 호출 시 스택영역에 할당되면서 실행된다. (Thread-0 스레드)
System.out.println(Thread.currentThread().getName() + ": start() 호출 후");
System.out.println(Thread.currentThread().getName() + ": main() end");
/*
main: main() start
main: start() 호출 전
main: start() 호출 후
main: main() end
Thread-0: run()
Thread-0 스레드가 run() 호출(main 스레드가 run() 호출 x)
*/
}
}
public class HelloThread extends Thread {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ": run()");
}
}
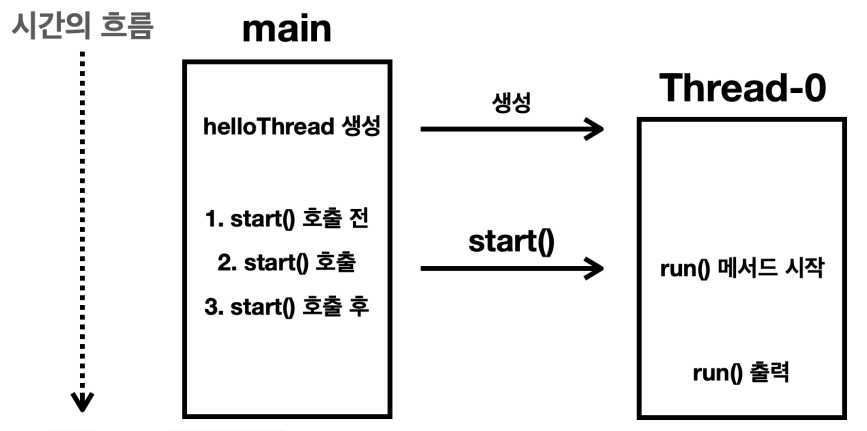
helloThread.start() 호출 시 main 스레드와 Thread-0 스레드가 동시에 실행된다. 스레드 간 실행 순서는 보장하지 않는다.
데몬 스레드
- 스레드
- 사용자 스레드(non-daemon 스레드)
- 프로그램의 주요 작업을 수행
- 모든 user 스레드가 종료되면 JVM도 종료
- 데몬 스레드
- 백그라운드에서 보조적인 작업을 수행
- 모든 user 스레드가 종료되면 데몬 스레드는 자동으로 종료
- Thread
- 사용자 스레드(non-daemon 스레드)
스레드 생성 방법
- Thread 상속
- 자바는 단일 상속만 허용하기에 이미 다른 클래스를 상속받고 있는 경우 Thread 클래스를 상속 받을 수 없다.
- Runnable 인터페이스 구현
- 다른 클래스를 상속받아도 문제없이 구현 가능
스레드의 생명주기
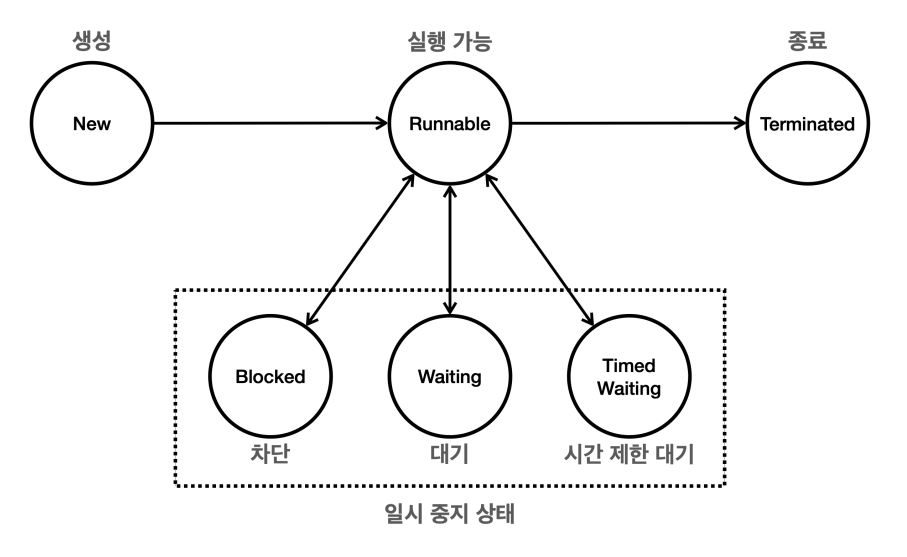
- New
- 스레드가 생성되었으나 아직 시작되지 않은 상태
- start() 메서드가 호출되지 않은 상태
- Runnable
- 실행 중이거나 실행 가능한 상태
- start() 메서드가 호출되면 스레드는 Runnable 상태로 들어간다.
- Runnable 상태에 있는 스레드는 스케줄러의 실행 대기열에 포함되어 있다가 차례로 CPU에서 실행된다
- Blocked(차단 상태)
- 스레드가 동기화 락을 기다리는 상태
- synchronized 코드 블록에 진입하려고 할 때, 다른 스레드가 이미 락을 가지고 있는 경우
- Waiting(대기 상태)
- 스레드가 무기한으로 다른 스레드의 작업을 기다리는 상태
- wait(), join() 메소드 호출될 때
- Timed Waiting(시간 제한 대기 상태)
- 스레드가 일정 시간 동안 다른 스레드의 작업을 기다리는 상태
- sleep, wait, join 메소드가 호출 될 때
- Terminate
- 스레드의 실행이 완료된 상태
- 스레드가 정상적으로 종료되거나 예외 발생하여 종료된 경우
- 스레드는 한 번 종료되면 다시 시작할 수 없다.
체크 예외 재정의
- Runnable 인터페이스의 run() 메서드를 구현할 때 InterruptedException 체크 예외를 밖으로 던질 수 없 는 이유 예외 재정의 규칙 때문이다.
체크 예외 재정의 규칙- 자식 클래스에 재정의된 메서드는 부모 메서드가 던질 수 있는 체크 예외의 하위 타입만을 던질 수 있다.
- 원래 메서드가 체크 예외를 던지지 않는 경우, 재정의된 메서드도 체크 예외를 던질 수 없다.
Join
Join Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public class JoinMainV0 {
public static void main(String[] args) {
log("Start");
Thread thread1 = new Thread(new Job(), "thread-1");
Thread thread2 = new Thread(new Job(), "thread-2");
thread1.start();
thread2.start();
log("End");
/*
16:43:16.068 [ main] Start
16:43:16.077 [ main] End
16:43:16.077 [ thread-1] 작업 시작
16:43:16.077 [ thread-2] 작업 시작
16:43:18.093 [ thread-2] 작업 완료
16:43:18.093 [ thread-1] 작업 완료
main 스레드가 thread-1 , thread-2 가 끝날때까지 기다리지 않는다.
main 스레드는 단지 start() 를 호출해서 다른 스레드를 실행만 하고 바로 자신의 다음 코드를 실행한다.
thread-1 , thread-2 가 종료된 다음에 main 스레드를 가장 마지막에 종료하려면?
=> JoinMainV3
*/
}
static class Job implements Runnable {
@Override
public void run() {
log("작업 시작");
sleep(2000);
log("작업 완료");
}
}
}
Join Code 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
public class JoinMainV3 {
public static void main(String[] args) throws InterruptedException {
log("Start");
SumTask task1 = new SumTask(1, 50);
SumTask task2 = new SumTask(51, 100);
Thread thread1 = new Thread(task1, "thread-1");
Thread thread2 = new Thread(task2, "thread-2");
thread1.start();
thread2.start();
// 스레드가 종료될 때 까지 대기
log("join() - main 스레드가 thread1, thread2 종료까지 대기한다. < main thread Waiting >");
thread1.join(); // InterruptedException 예외 던짐
thread2.join(); // InterruptedException 예외 던짐
log("main 스레드 대기 완료");
log("task1.result = " + task1.sum );
log("task2.result = " + task2.sum);
int sumAll = task1.sum + task2.sum;
log("task1 + task2 = " + sumAll);
log("End");
/*
17:10:03.223 [ main] Start
17:10:03.235 [ main] join() - main 스레드가 thread1, thread2 종료까지 대기
17:10:03.235 [ thread-1] 작업 시작
17:10:03.235 [ thread-2] 작업 시작
17:10:05.256 [ thread-1] 작업 완료: sum= 1275
17:10:05.256 [ thread-2] 작업 완료: sum= 3775
17:10:05.257 [ main] main 스레드 대기 완료
17:10:05.258 [ main] task1.result = 1275
17:10:05.259 [ main] task2.result = 3775
17:10:05.260 [ main] task1 + task2 = 5050
17:10:05.260 [ main] End
*/
}
static class SumTask implements Runnable {
private final int FIRST;
private final int LAST;
int sum;
public SumTask(int first, int last) {
this.FIRST = first;
this.LAST = last;
this.sum = 0;
}
@Override
public void run() {
log("작업 시작");
sleep(2000);
for (int i = FIRST; i <= LAST; i++) {
sum += i;
}
log("작업 완료: sum= " + sum);
}
}
}
join() 을 호출하는 스레드는 대상 스레드가 TERMINATED 상태가 될 때 까지 대기한다.
다른 스레드가 완료될 때 까지 무기한 기다리는 단점 존재
Join Code 3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
public class JoinMainV4 {
public static void main(String[] args) throws InterruptedException {
log("Start");
SumTask task1 = new SumTask(1, 50);
Thread thread1 = new Thread(task1, "thread-1");
thread1.start();
// 스레드가 종료될 때 까지 대기
log("join(5000) - main 스레드가 최대 5초 동안 thread1 종료까지 대기한다.");
thread1.join(5000);
log("main 스레드 대기 완료");
log("task1.sum = " + task1.sum);
}
static class SumTask implements Runnable {
private final int FIRST;
private final int LAST;
int sum;
public SumTask(int first, int last) {
this.FIRST = first;
this.LAST = last;
this.sum = 0;
}
@Override
public void run() {
log("작업 시작");
sleep(2000);
for (int i = FIRST; i <= LAST; i++) {
sum += i;
}
log("작업 완료: sum= " + sum);
}
}
}
join(ms) 을 호출하는 스레드는 대상 스레드가 ms 동안 대기한다.
ms 이전에 해당 스레드가 종료되면 ms 동안 기다리지 않고 호출한 스레드가 실행된다.
Interupt
Inturrupt Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
public class ThreadStopMainV1 {
public static void main(String[] args) {
MyTask myTask = new MyTask();
Thread thread = new Thread(myTask, "work");
thread.start();
sleep(4000);
log("작업 중단 지시 runFlag=false");
myTask.runFlag = false;
/*
17:55:21.971 [ work] 작업중
17:55:24.978 [ work] 작업중
17:55:25.964 [ main] 작업 중단 지시 runFlag=false
17:55:27.990 [ work] 자원 정리
17:55:27.991 [ work] 작업 종료
문제점
작업 중단 지시 2초 정도 이후에 자원을 정리하고 작업을 종료한다.
main 스레드가 runFlag 를 false 로 변경해도, work 스레드는 sleep(3000) 을 통해 3초간 잠들어 있기 때문이다.
어떻게 하면 sleep() 처럼 스레드가 대기하는 상태에서 스레드를 깨우고, 작업도 빨리 종료할 수 있을까?
=>
*/
}
static class MyTask implements Runnable {
volatile boolean runFlag = true;
@Override
public void run() {
while (runFlag) {
log("작업중");
sleep(3000);
}
log("자원 정리");
log("작업 종료");
}
}
}
Inturrupt Code 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
public class ThreadStopMainV2 {
public static void main(String[] args) {
MyTask myTask = new MyTask();
Thread myTaskThread = new Thread(myTask, "work");
myTaskThread.start();
sleep(4000);
log("작업 중단 지시 myTaskThread.interrupt()");
myTaskThread.interrupt();
log("work 스레드 인터럽트 상태1 = " + myTaskThread.isInterrupted());
/*
18:04:31.477 [ work] 작업 중
18:04:34.494 [ work] 작업 중
18:04:35.475 [ main] 작업 중단 지시 myTaskThread.interrupt()
18:04:35.487 [ main] work 스레드 인터럽트 상태1 = true
18:04:35.487 [ work] work 스레드 인터럽트 상태2 = false
18:04:35.488 [ work] interrupt message=sleep interrupted
18:04:35.489 [ work] state=RUNNABLE
18:04:35.490 [ work] 자원 정리
18:04:35.490 [ work] 작업 종료
*/
}
static class MyTask implements Runnable {
@Override
public void run() {
try {
while (true) {
log("작업 중");
Thread.sleep(3000);
}
} catch (InterruptedException e) {
log("work 스레드 인터럽트 상태2 = " + Thread.currentThread().isInterrupted());
log("interrupt message=" + e.getMessage());
log("state=" + Thread.currentThread().getState());
}
log("자원 정리");
log("작업 종료");
}
}
}
Inturrupt Code 3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
public class ThreadStopMainV3 {
public static void main(String[] args) {
MyTask myTask = new MyTask();
Thread myTaskThread = new Thread(myTask, "work");
myTaskThread.start();
sleep(100);
log("작업 중단 지시 - myTaskThread.interrupt()");
myTaskThread.interrupt();
log("work 스레드 인터럽트 상태1 = " + myTaskThread.isInterrupted());
/*
10:41:13.651 [ work] 작업중 ...
10:41:13.651 [ work] 작업중
10:41:13.652 [ main] 작업 중단 지시 - myTaskThread.interrupt()
10:41:13.652 [ work] 작업중
10:41:13.652 [ main] work 스레드 인터럽트 상태1 = true
10:41:13.652 [ work] work 스레드 인터럽트 상태2 = true
10:41:13.652 [ work] 자원 정리 시도
10:41:13.652 [ work] 자원 정리 실패 - 자원 정리 중 인터럽트 발생
10:41:13.652 [ work] work 스레드 인터럽트 상태3 = false
10:41:13.652 [ work] 작업 종료
*/
}
static class MyTask implements Runnable {
@Override
public void run() {
while (!Thread.currentThread().isInterrupted()) {
log("작업중");
}
log("work 스레드 인터럽트 상태2 = " + Thread.currentThread().isInterrupted());
try {
log("자원 정리 시도");
Thread.sleep(1000); // 인터럽트 상태가 ture 일 경우 sleep() 을 호출한다면, 해당 코드에서 인터럽트 예외가 발생하게 된다.
log("자원 정리 완료");
} catch (InterruptedException e) {
log("자원 정리 실패 - 자원 정리 중 인터럽트 발생");
log("work 스레드 인터럽트 상태3 = " + Thread.currentThread().isInterrupted());
// 스레드의 인터럽트 상태를 정상적으로 돌리지 않으면 계속 인터럽트가 발생하기에 내부에서 false 로 변환한다.
}
log("작업 종료");
}
}
}
Inturrupt Code 4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
public class ThreadStopMainV4 {
public static void main(String[] args) {
MyTask myTask = new MyTask();
Thread myTaskThread = new Thread(myTask, "work");
myTaskThread.start();
sleep(100);
log("작업 중단 지시 - myTaskThread.interrupt()");
myTaskThread.interrupt();
log("work 스레드 인터럽트 상태1 = " + myTaskThread.isInterrupted());
}
static class MyTask implements Runnable {
@Override
public void run() {
while (!Thread.interrupted()) {
log("작업중");
}
log("work 스레드 인터럽트 상태2 = " + Thread.currentThread().isInterrupted());
try {
log("자원 정리 시도");
Thread.sleep(1000);
// 인터럽트 상태가 ture 일 경우 sleep() 을 호출한다면, 해당 코드에서 인터럽트 예외가 발생하게 된다.
log("자원 정리 완료");
} catch (InterruptedException e) {
log("자원 정리 실패 - 자원 정리 중 인터럽트 발생");
log("work 스레드 인터럽트 상태3 = " + Thread.currentThread().isInterrupted());
// 스레드의 인터럽트 상태를 정상적으로 돌리지 않으면 계속 인터럽트가 발생하기에 내부에서 false 로 변환한다.
}
log("작업 종료");
}
}
}
isInterrupted()
특정 스레드의 상태를 변경하지 않고 확인만 한다.
Thread.interrupted()
현재 스레드의 인터럽트 상태를 확인하고, 인터럽트 상태를 초기화한다.
인터럽트가 true 일 경우 false 로 초기화한다.
Printer Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
public class MyPrinterV2 {
public static void main(String[] args) {
Printer printer = new Printer();
Thread printerThread = new Thread(printer, "printer");
printerThread.start();
Scanner scanner = new Scanner(System.in);
while (true) {
log("프린트할 문서를 입력하세요. 종료 (q): ");
String input = scanner.nextLine();
if ("q".equals(input)) {
printerThread.interrupt();
break;
}
printer.addJob(input);
}
}
static class Printer implements Runnable {
Queue<String> jobQueue = new ConcurrentLinkedQueue<>();
@Override
public void run() {
while (!Thread.interrupted()) {
if (jobQueue.isEmpty()) continue;
try {
String job = jobQueue.poll();
log("출력 시작: " + job + ", 대기 문서:" + jobQueue);
Thread.sleep(3000);
log("출력 완료: " + job);
} catch (InterruptedException e) {
log("인터럽트!");
break;
}
}
log("프린터 종료");
}
void addJob(String input) {
jobQueue.offer(input);
}
}
}
main 스레드: 사용자 입력을 받는다.
printer 스레드: 사용자의 입력을 출력한다.
Yield()
- Thread.yield()
- 현재 실행 중인 스레드가 자발적으로 CPU 를 양보하여 다른 스레드가 실행될 수 있도록 한다.
- yield() 메서드를 호출한 스레드는 RUNNABLE 상태를 유지하면서 CPU 를 양보한다.
- yield() 는 RUNNABLE 상태를 유지하기 때문에, 쉽게 이야기해서 양보할 사람이 없다면 본인 스레드가 계속 실행될 수 있다.
Printer Code 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
public class MyPrinterV3 {
public static void main(String[] args) {
Logger logger = new Logger();
Thread loggerThread = new Thread(logger, "logger");
loggerThread.start();
Printer printer = new Printer();
Thread printerThread = new Thread(printer, "printer");
printerThread.start();
Scanner scanner = new Scanner(System.in);
while (true) {
log("프린트할 문서를 입력하세요. 종료 (q): ");
String input = scanner.nextLine();
if ("q".equals(input)) {
printerThread.interrupt();
loggerThread.interrupt();
break;
}
printer.addJob(input);
}
}
static class Printer implements Runnable {
Queue<String> jobQueue = new ConcurrentLinkedQueue<>();
@Override
public void run() {
while (!Thread.interrupted()) {
if (jobQueue.isEmpty()) {
// jobQueue 에 작업이 비어있으면 yield() 를 호출해서, 다른 스레드에 작업을 양보
Thread.yield();
continue;
}
try {
String job = jobQueue.poll();
log("출력 시작: " + job + ", 대기 문서:" + jobQueue);
Thread.sleep(3000);
log("출력 완료: " + job);
} catch (InterruptedException e) {
log("프린터 인터럽트!");
break;
}
}
log("프린터 종료");
}
void addJob(String input) {
jobQueue.offer(input);
}
}
static class Logger implements Runnable {
@Override
public void run() {
while (!Thread.interrupted()) {
log("로거 실행중");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
log("로거 인터럽트!");
break;
}
}
log("로거 종료");
}
}
}
Thread.yield()를 추가하여 Printer 스레드가 CPU를 양보하여 Logger 스레드가 더 자주 실행될 수 있게 된다.
반면, Thread.yield()를 삭제하면 Printer 스레드가 CPU를 계속 점유할 가능성이 높아져 Logger 스레드의 실행 빈도가 줄어들 수 있다.
volatile
Volatile Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public class VolatileFlagMain {
public static void main(String[] args) {
MyTask myTask = new MyTask();
Thread myThread = new Thread(myTask, "myTask");
log("runFlag= " + myTask.runFlag);
myThread.start();
sleep(1000);
log("runFlag: true → false");
myTask.runFlag = false;
log("runFlag= " + myTask.runFlag);
log("메인 스레드 종료");
}
static class MyTask implements Runnable {
boolean runFlag = true;
@Override
public void run() {
log("task 시작");
while (runFlag) {
log("실행중");
}
log("task 종료");
}
}
/*
15:40:55.367 [ main] runFlag = true
15:40:55.367 [ work] task 시작
15:40:56.374 [ main] runFlag를 false로 변경 시도
15:40:56.374 [ main] runFlag = false
15:40:56.375 [ main] main 종료
내 코드에서는 "task 종료"가 출력되었지만 실행환경에 따라 미출력될 수 있다.
*/
}
- 상위 코드에 대한 예상 메모리 접근 방식
- 실제 메모리 접근 방식
- 현대의 CPU 대부분은 코어 단위로 캐시 메모리를 각각 보유하고 있고, 처리 성능을 개선하기 위해 중간에 캐시 메모리를 사용한다.
![]()
![]()
- 캐시 메모리를 메인 메모리에 반영하거나, 메인 메모리의 변경 내역을 캐시 메모리에 다시 불러오는 것은 CPU 설계 방식과 실행 환경에 따라 다르다.
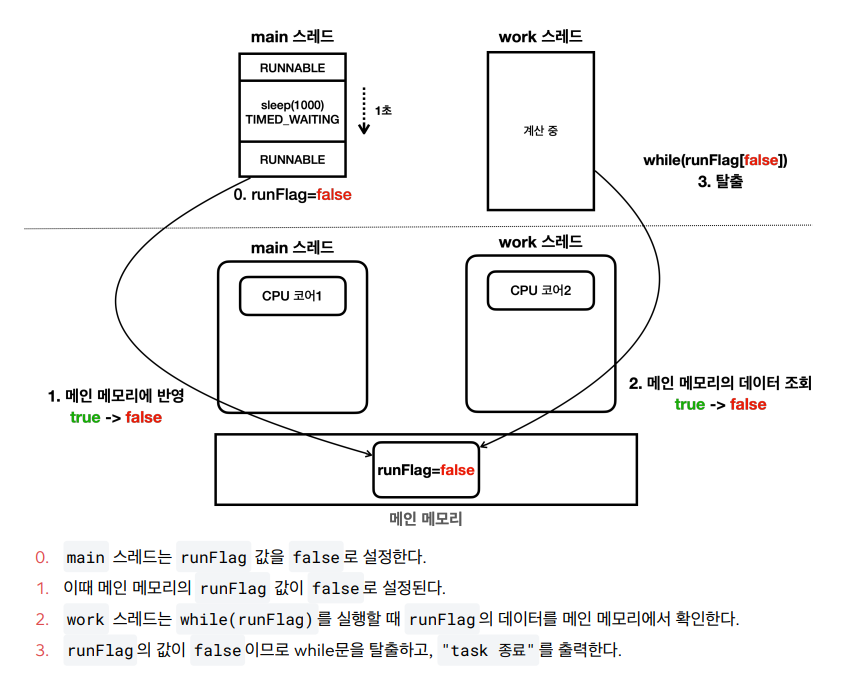
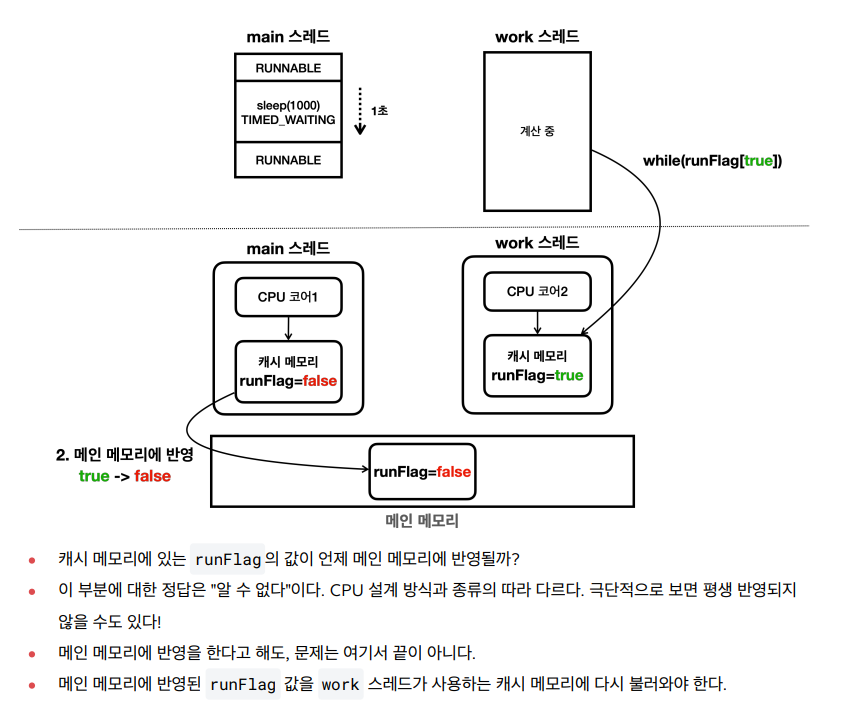
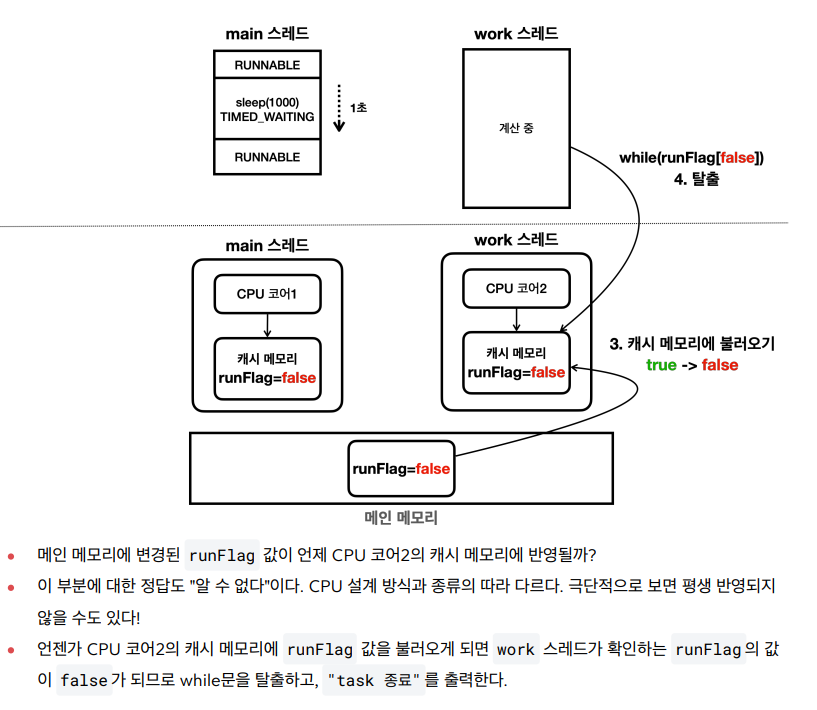
메모리 가시성
- 멀티 스레드 환경에서 한 스레드가 변경한 값이 다른 스레드에서 언제 보이는지에 대한 문제
- 해당 문제를 해결하기위해서는 값을 읽을 때, 쓸 때 모두 메인 메모리에 직접 접근하면 된다.
- 자바에서 제공하는 키워드 volatile
- 여러 스레드에서 같은 값을 읽고 써야 한다면 volatile 키워드를 사용하면 된다.
- 단 캐시 메모리를 사용할 때 보다 성능이 느려지는 단점이 있기 때문에 꼭! 필요한 곳에만 사용하는 것이 좋다.
Volatile Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
public class VolatileCountMain {
public static void main(String[] args) {
MyTask myTask = new MyTask();
Thread t = new Thread(myTask, "work");
t.start();
sleep(1000);
myTask.flag = false;
log("flag = " + myTask.flag + ", count = " + myTask.count + " in main");
/*
volatile x (메모리 가시성 확인)
15:25:29.547 [ work] flag = true, count = 100000000 in while()
15:25:29.777 [ work] flag = true, count = 200000000 in while()
15:25:29.986 [ work] flag = true, count = 300000000 in while()
15:25:30.173 [ work] flag = true, count = 400000000 in while()
15:25:30.309 [ main] flag = false, count = 472079158 in main
15:25:30.352 [ work] flag = true, count = 500000000 in while()
15:25:30.352 [ work] flag = false, count = 500000000 종료
volatile o
15:29:23.806 [ work] flag = true, count = 100000000 in while()
15:29:23.985 [ main] flag = false, count = 123342843 in main
15:29:23.985 [ work] flag = false, count = 123342843 종료
*/
}
static class MyTask implements Runnable {
boolean flag = true;
long count;
// volatile boolean flag = true;
// volatile long count;
@Override
public void run() {
while (flag) {
count++;
// 1억번에 한 번씩 출력한다.
if (count % 100_000_000 == 0) {
log("flag = " + flag + ", count = " + count + " in while()");
}
}
log("flag = " + flag + ", count = " + count + " 종료");
}
}
}
자바 메모리 모델(JMM: Java Memory Model)
- 자바 프로그램이 어떻게 메모리에 접근하고 수정할 수 있는지를 규정
- 특히 멀티 스레드 프로그래밍에서 스레드 간의 상호작용을 정의
happens-before
- JMM에서 스레드 간의 작업 순서를 정의한다.
- happens-before 관계는 스레드 간의 메모리 가시성을 보장하는 규칙이다.
- A 스레드가 B 스레드보다 happens-before 관계에 있다면 A 스레드에서 변경된 내용은 B 스레드가 시작되기 전에 모두 메모리에 반영된다.
happens-before 관계를 활용하여 프로그래머가 멀티스레드 프로그램을 작성할 때 예상치 못한 동작을 피할 수 있다.
- 스레드 시작 규칙
- 한 스레드에서 Thread.start() 를 호출하면, 해당 스레드 내의 모든 작업은 start() 호출 이후에 실행된 작업보다 happens-before 관계가 성립한다.
1 2
Thread t = new Thread(task); t.start();
- 여기에서 start() 호출 전에 수행된 모든 작업은 새로운 스레드가 시작된 후의 작업보다 happens-before 관계를 가진다.
- 스레드 종료 규칙
- 한 스레드에서 Thread.join() 을 호출하면, join 대상 스레드의 모든 작업은 join() 이 반환된 후의 작업보다 happens-before 관계를 가진다. 예를 들어, thread.join() 호출 전에 thread 의 모든 작업이 완료되어야 하며, 이 작업은 join() 이 반환된 후에 참조 가능하다.
- 인터럽트 규칙
- 한 스레드에서 Thread.interrupt() 를 호출하는 작업이, 인터럽트된 스레드가 인터럽트를 감지하는 시점의 작업보다 happens-before 관계가 성립한다. 즉, interrupt() 호출 후, 해당 스레드의 인터럽트 상태를 확인하는 작업이 happens-before 관계에 있다. 만약 이런 규칙이 없다면 인터럽트를 걸어도, 한참 나중에 인터럽트가 발생할 수 있다.
- 객체 생성 규칙
- 객체의 생성자는 객체가 완전히 생성된 후에만 다른 스레드에 의해 참조될 수 있도록 보장한다. 즉, 객체의 생성자에서 초기화된 필드는 생성자가 완료된 후 다른 스레드에서 참조될 때 happens-before 관계가 성립한다.
- 모니터 락 규칙
- 한 스레드에서 synchronized 블록을 종료한 후, 그 모니터 락을 얻는 모든 스레드는 해당 블록 내의 모든 작업을 볼 수 있다. 예를 들어, synchronized(lock) { … } 블록 내에서의 작업은 블록을 나가는 시점에 happensbefore 관계가 형성된다. 뿐만 아니라 ReentrantLock 과 같이 락을 사용하는 경우에도 happens-before 관계가 성립한다.
- 전이 규칙 (Transitivity Rule)
- 만약 A가 B보다 happens-before 관계에 있고, B가 C보다 happens-before 관계에 있다면, A는 C보다 happensbefore 관계에 있다.
정리
volatile 또는 스레드 동기화 기법(synchronized, ReentrantLock)을 사용하면 메모리 가시성의 문제가 발생하지 않는다.
동기화 - synchronized
- 멀티스레드를 사용할 때, 가장 주의해야할 점은 같은 자원(리소스)에 여러 스레드가 동시에 접근할 때 발생하는 동시성 문제이다.
- 공유 자원: 여러 스레드가 접근하는 자원(e.g. 인스턴스 필드)
- 멀티스레드를 사용할 때는 이런 공유 자원에 대한 접근을 적절하게 동기화(synchronization)해서 동시성 문제가 발생하지 않게 방지하는 것이 중요하다.
동시성 문제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
public interface BankAccount {
boolean withdraw(int amount);
int getBalance();
}
public class BankAccountV1 implements BankAccount {
private int balance;
public BankAccountV1(int initialBalance) {
this.balance = initialBalance;
}
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
log("[검증 시작] 출금액: " + amount + ", 잔액: " + balance);
if (balance < amount) {
log("[검증 실패] 출금액: " + amount + ", 잔액: " + balance);
return false;
}
log("[검증 완료] 출금액: " + amount + ", 잔액: " + balance);
sleep(1000); // 출금에 걸리는 시간으로 가정
balance = balance - amount;
log("[출금 완료] 출금액: " + amount + ", 변경 잔액: " + balance);
log("거래 종료");
return true;
}
@Override
public int getBalance() {
return balance;
}
}
public class WithdrawTask implements Runnable {
private BankAccount bankAccount;
private int amount;
public WithdrawTask(BankAccount bankAccount, int amount) {
this.bankAccount = bankAccount;
this.amount = amount;
}
@Override
public void run() {
bankAccount.withdraw(amount);
}
}
public class BankMain {
public static void main(String[] args) throws InterruptedException {
BankAccount account = new BankAccountV1(1000);
// 한 계좌에서 출금을 2번한다.
Thread t1 = new Thread(new WithdrawTask(account, 800), "t1");
Thread t2 = new Thread(new WithdrawTask(account, 800), "t2");
t1.start();
t2.start();
// 검증 완료까지 잠시 대기한다.
sleep(500);
log("t1 state: " + t1.getState());
log("t2 state: " + t2.getState());
// main 스레드는 join() 을 사용해서 t1 , t2 스레드가 출금을 완료한 이후에 최종 잔액을 확인한다.
t1.join();
t2.join();
log("최종 잔액: " + account.getBalance());
/*
동시성 문제 발생
16:40:01.144 [ t1] 거래 시작: BankAccountV1
16:40:01.144 [ t2] 거래 시작: BankAccountV1
16:40:01.155 [ t1] [검증 시작] 출금액: 800, 잔액: 1000
16:40:01.155 [ t2] [검증 시작] 출금액: 800, 잔액: 1000
16:40:01.157 [ t1] [검증 완료] 출금액: 800, 잔액: 1000
16:40:01.157 [ t2] [검증 완료] 출금액: 800, 잔액: 1000
16:40:01.630 [ main] t1 state: TIMED_WAITING
16:40:01.630 [ main] t2 state: TIMED_WAITING
16:40:02.166 [ t1] [출금 완료] 출금액: 800, 변경 잔액: 200
16:40:02.166 [ t2] [출금 완료] 출금액: 800, 변경 잔액: -600
16:40:02.167 [ t1] 거래 종료
16:40:02.168 [ t2] 거래 종료
16:40:02.170 [ main] 최종 잔액: -600
*/
}
}
t1이 아직 잔액(balance)를 줄이지 못했기 때문에 t2는 검증 로직에서 현재 잔액을 1000원으로 확인한다.
참고: balance 값에 volatile 을 도입하면 문제가 해결되지 않을까? 그렇지 않다. volatile 은 한 스레드가 값을 변경했을 때 다른 스레드에서 변경된 값을 즉시 볼 수 있게 하는 메모리 가시성의 문제를 해결할 뿐이다. 예를 들어 t1 스레드가 balance 의 값을 변경했을 때, t2 스레드에서 balance 의 변경된 값을 즉시 확인해도 여전히 같은 문제가 발생한다. 이 문제는 메모리 가시성 문제를 해결해도 여전히 발생한다.
- 이런 문제가 발생하는 근본 원인은 여러 스레드가 함께 사용하는 공유 자원을 여러 단계로 나누어 사용하기 때문이다.
- 공유 자원
- balance는 여러 스레드가 함께 사용하는 공유 자원이다.
- A 스레드가 공유 자원에 접근하는 로직을 실행중일 때, B 스레드가 공유자원에 접근하면 안된다.
임계 영역(Cretical Section)
- 여러 스레드가 동시에 접근해서는 안되는 공유 자원을 접근하거나 수정하는 부분
- 출금을 진행할 때 잔액을 검증하는 단계부터 잔액의 계산을 완료할 때 까지가 임계 영역이다. 이런 임계 영역은 한 번에 하나의 스레드만 접근할 수 있도록 안전하게 보호해야 한다.
- 자바는 synchronized 키워드를 통해 아주 간단히 임계 영역을 보호할 수 있다.
synchronized Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
/**
* 각 메소드에 synchronized 키워드 추가
* 메서드를 synchronized 로 선언해서, 메서드에 접근하는 스레드가 하나뿐이도록 보장한다.
*/
public class BankAccountV2 implements BankAccount {
private int balance;
public BankAccountV2(int initialBalance) {
this.balance = initialBalance;
}
@Override
public synchronized boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
log("[검증 시작] 출금액: " + amount + ", 잔액: " + balance);
if (balance < amount) {
log("[검증 실패] 출금액: " + amount + ", 잔액: " + balance);
return false;
}
log("[검증 완료] 출금액: " + amount + ", 잔액: " + balance);
sleep(1000); // 출금에 걸리는 시간으로 가정. sleep 을 주석처리 해도 동시성 문제 해결 불가능하다.
balance = balance - amount;
log("[출금 완료] 출금액: " + amount + ", 변경 잔액: " + balance);
log("거래 종료");
return true;
}
@Override
public synchronized int getBalance() {
return balance;
}
}
public class BankMain {
public static void main(String[] args) throws InterruptedException {
// BankAccount account = new BankAccountV1(1000);
BankAccount account = new BankAccountV2(1000); // 인스턴스 락 존재
// 한 계좌에서 출금을 2번한다.
Thread t1 = new Thread(new WithdrawTask(account, 800), "t1");
Thread t2 = new Thread(new WithdrawTask(account, 800), "t2");
t1.start();
t2.start();
// 검증 완료까지 잠시 대기한다.
sleep(500);
log("t1 state: " + t1.getState());
log("t2 state: " + t2.getState());
// main 스레드는 join() 을 사용해서 t1 , t2 스레드가 출금을 완료한 이후에 최종 잔액을 확인한다.
t1.join();
t2.join();
log("최종 잔액: " + account.getBalance());
/*
synchronized 키워드로 인한 동시성 문제 해결
17:15:38.879 [ t1] 거래 시작: BankAccountV2
17:15:38.889 [ t1] [검증 시작] 출금액: 800, 잔액: 1000
17:15:38.890 [ t1] [검증 완료] 출금액: 800, 잔액: 1000
17:15:39.369 [ main] t1 state: TIMED_WAITING
17:15:39.369 [ main] t2 state: BLOCKED
17:15:39.891 [ t1] [출금 완료] 출금액: 800, 변경 잔액: 200
17:15:39.892 [ t1] 거래 종료
17:15:39.893 [ t2] 거래 시작: BankAccountV2
17:15:39.895 [ t2] [검증 시작] 출금액: 800, 잔액: 200
17:15:39.896 [ t2] [검증 실패] 출금액: 800, 잔액: 200
17:15:39.897 [ main] 최종 잔액: 200
*/
}
}
- 모니터 락
- 모든 인스턴스는 내부에 자신만의 락(lock)을 가지고 있는데 해당 락을 모니터 락(Monitor Lock) 이라고 한다.
- 스레드가 synchronized 키워드가 있는 메서드에 진입하려면 반드시 해당 인스턴스의 락이 있어야 한다.
- 내부 흐름
- t1: withdraw() 호출 → 인스턴스 lock 획득 → t2: lock 획득 시도 → 해당 lock을 t1이 가지고 있어 lock을 획득할 때까지 RUNNABLE 상태에서 BLOCKED 상태로 무한정 대기 → t1: 메소드 호출 종료 후 lock 반납 → t2: lock 획득 성공 → t2: BLOCKED 상태에서 RUNNABLE 상태로 전환 → t2: 코드 실행
- 참고
- 락을 획득하는 순서는 보장되지 않는다.
- volatile 를 사용하지 않아도 synchronized 안에서 접근하는 변수의 메모리 가시성 문제는 해결된다.
synchronized Code 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
public class BankAccountV3 implements BankAccount {
private int balance;
public BankAccountV3(int initialBalance) {
this.balance = initialBalance;
}
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
synchronized (this) {
log("[검증 시작] 출금액: " + amount + ", 잔액: " + balance);
if (balance < amount) {
log("[검증 실패] 출금액: " + amount + ", 잔액: " + balance);
return false;
}
log("[검증 완료] 출금액: " + amount + ", 잔액: " + balance);
sleep(1000); // 출금에 걸리는 시간으로 가정. sleep 을 주석처리 해도 동시성 문제 해결 불가능하다.
balance = balance - amount;
log("[출금 완료] 출금액: " + amount + ", 변경 잔액: " + balance);
}
log("거래 종료");
return true;
}
@Override
public synchronized int getBalance() {
return balance;
}
}
필요한 코드만 안전한 임계 영역으로 만든다.
Test Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
public class SyncTest1BadMain {
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Runnable task = new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
counter.increment();
}
}
};
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
thread1.start();
thread2.start();
// join() 을 호출하는 main 스레드는 해당 스레드들의 상태가 terminated 가 될 때까지 기다린다.
thread1.join();
thread2.join();
System.out.println("결과: " + counter.getCount());
/*
결과: 20000 이하
공유 변수 경합 상태에 의해 두 스레드가 계산한 값을 거의 동시에 count 에 저장하게 되면,
실제로는 두 번 증가해야 할 count 가 한 번만 증가하게 된다.
*/
}
static class Counter {
private int count = 0;
public void increment() {
count = count + 1;
}
public int getCount() {
return count;
}
}
}
Test Code 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
/*
실행 결과 예측
*/
public class SyncTest2BadMain {
public static void main(String[] args) throws InterruptedException {
MyCounter myCounter = new MyCounter();
Runnable task = new Runnable() {
@Override
public void run() {
myCounter.count();
}
};
Thread thread1 = new Thread(task, "Thread-1");
Thread thread2 = new Thread(task, "Thread-2");
thread1.start();
thread2.start();
}
static class MyCounter {
public void count() {
int localValue = 0;
for (int i = 0; i < 1000; i++) {
localValue = localValue + 1;
}
log("결과: " + localValue);
}
}
/*
18:32:10.673 [ Thread-1] 결과: 1000
18:32:10.673 [ Thread-2] 결과: 1000
localValue 는 지역 변수
지역 변수는 절대로! 다른 스레드와 공유되지 않는다.
*/
}
Test Code 3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class Immutable {
private final int value;
public Immutable(int value) {
this.value = value;
}
public int getValue() {
eturn value;
}
}
/*
value 필드(멤버 변수)는 공유되는 값이다. 멀티스레드 상황에서 문제가 될 수 있을까?
여러 스레드가 공유 자원에 접근하는 것 자체는 사실 문제가 되지 않는다. 진짜 문제는 공유 자원을 사용하는 중간에 다른 스레드가 공유 자원의 값을 변경해버리기 때문에 발생한다. 결국 변경이 문제가 되는 것이다.
value는 상수이므로 변경 자체가 불가능하여 문제가 되지 않는다.
*/
⭐ 정리
- synchronized: 임계영역에서 하나의 스레드만 보장하는 것
- 임계영역: 여러 스레드가 동시에 접근해서는 안되는 공유 자원을 접근하거나 수정하는 부분
고급 동기화 - concurrent.Lock
- synchronized 단점
- 무한 대기: BLOCKED 상태의 스레드는 락이 풀릴 때 까지 무한 대기한다.
- 특정 시간까지만 대기하는 타임아웃이 없다.
- 중간에 인터럽트를 걸 수 없다.
- 공정성: 락이 돌아왔을 때 BLOCKED 상태의 여러 스레드 중에 어떤 스레드가 락을 획득할 지 알 수 없다.
- 무한 대기: BLOCKED 상태의 스레드는 락이 풀릴 때 까지 무한 대기한다.
- LockSupport 를 사용하여 synchronized 의 가장 큰 단점인 무한 대기 문제를 해결할 수 있다.
LockSupport
- 스레드를 waiting 상태로 변경(CPU 실행 스케줄리에 들어가지 않음)
- 무한 대기하지 않는 락 기능을 만들 수 있다.
- LockSupport 의 대표적인 기능
- park()
- 스레드를 waiting 상태로 변경
- parkNanos(nanos)
- 스레드를 나노초 동안만 TIMED_WAITING 상태로 변경한다. 나노초가 지나면 RUNNABLE 상태로 변경된다.
- park()
- BLOCKED vs WAITING
- BLOCKED
- 인터럽트가 걸려도 대기 상태를 빠져나오지 못한다.
- 자바의 synchronized 에서 락을 획득하기 위해 대기할 때 사용된다.
- WAITING, TIMED_WAITING
- 인터럽트가 걸리면 대기 상태를 빠져나온다. 그래서 RUNNABLE 상태로 변한다.
- 스레드가 특정 조건이나 시간 동안 대기할 때 발생하는 상태이다.
- Thread.join(), LockSupport.park(), Object.wait() 와 같은 메서드 호출 시 WAITING 상태가 된다.
- Thread.sleep(ms), Object.wait(long timeout),Thread.join(long millis), LockSupport.parkNanos(ns) 등과 같은 시간 제한이 있는 대기 메서드를 호출할 때 TIMED_WAITING 상태가 된다.
- BLOCKED
- 대기( WAITING ) 상태와 시간 대기 상태( TIMED_WAITING )는 서로 짝이 있다.
- WAITING
- Thread.join()
- Thread.park()
- Object.wait()
- TIMED_WAITING
- Thread.join(long millis)
- Thread.parkNanos(long millis)
- Object.wait(long timeout)
- WAITING
- BLOCKED , WAITING , TIMED_WAITING 상태 모두 스레드가 대기하며, 실행 스케줄링에 들어가지 않기 때문에, CPU 입장에서 보면 실행하지 않는 비슷한 상태이다.
- BLOCKED 상태는 synchronized 에서만 사용하는 특별한 대기 상태라고 이해하면 된다.
- WAITING, TIMED_WAITING 상태는 범용적으로 활용할 수 있는 대기 상태라고 이해하면 된다.
ReentrantLock
- Lock 인터페이스의 대표적인 구현체
- 스레드가 공정하게 락을 얻을 수 있는 모드를 제공한다.
1
2
3
4
5
6
7
8
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
- Lock 인터페이스는 동시성 프로그래밍에서 쓰이는 안전한 임계 영역을 위한 락을 구현하는데 사용된다.
void lock(): 락을 획득한다. 만약 다른 스레드가 이미 락을 획득했다면, 락이 풀릴 때까지 현재 스레드는 대기( WAITING )한 다. 이 메서드는 인터럽트에 응답하지 않는다.void lockInterruptibly(): 락 획득을 시도하되, 다른 스레드가 인터럽트할 수 있도록 한다. 만약 다른 스레드가 이미 락을 획득했다면, 현재 스레드는 락을 획득할 때까지 대기한다. 대기 중에 인터럽트가 발생하면 InterruptedException 이 발생하며 락 획득을 포기한다.boolean tryLock(): 락 획득을 시도하고, 즉시 성공 여부를 반환한다. 만약 다른 스레드가 이미 락을 획득했다면 false 를 반환하고, 그렇지 않으면 락을 획득하고 true 를 반환한다.boolean tryLock(long time, TimeUnit unit): 주어진 시간 동안 락 획득을 시도한다. 주어진 시간 안에 락을 획득하면 true 를 반환한다. 주어진 시간이 지나도 락을 획득하지 못한 경우 false 를 반환한다. 인터럽트 발생 시, 락 획득을 포기한다.void unlock(): 락을 해제한다. 락을 해제하면 락 획득을 대기 중인 스레드 중 하나가 락을 획득할 수 있게 된다. 락을 획득한 스레드가 호출해야 하며, 그렇지 않으면 IllegalMonitorStateException 이 발생할 수 있다.Condition newCondition(): Condition 객체를 생성하여 반환한다. Condition 객체는 락과 결합되어 사용되며, 스레드가 특정 조건을 기다리거나 신호를 받을 수 있도록 한다. 이는 Object 클래스의 wait , notify , notifyAll 메서드와 유사한 역할을 한다.여기서 사용하는 락은 객체 내부에 있는 모니터 락이 아니다.
- 참고
- WAITING 상태의 스레드에 인터럽트가 발생하면 대기 상태를 빠져나온다고 배웠는데, lock() 설명을 보면 WAITING 상태인데 인터럽트에 응하지 않는다고 되어있다. 아래와 같은 이유로 인터럽트를 무시한다.
- lock() 호출 → 인터럽트 발생 → 짧게 WAITING 에서 RUNNABLE 상태로 변환 → lock() 메소드 안에서 해당 스레드를 다시 WAITING 상태로 변경
Lock 인터페이스는 synchronized 블록보다 더 많은 유연성을 제공하며, 특히 락을 특정 시간 만큼만 시도하거나, 인터럽트 가능한 락을 사용할 때 유용하다.
- 비공정 모드 락
- 성능 우선: 락을 획득하는 속도가 빠르다.
- 선점 가능: 새로운 스레드가 기존 대기 스레드보다 먼저 락을 획득할 수 있다.
- 기아 현상 가능성: 특정 스레드가 계속해서 락을 획득하지 못할 수 있다.
- 공정 모드 락
- 공정성 보장: 대기 큐에서 먼저 대기한 스레드가 락을 먼저 획득한다.
- 기아 현상 방지: 모든 스레드가 언젠가 락을 획득할 수 있게 보장된다.
- 성능 저하: 락을 획득하는 속도가 느려질 수 있다.
lock, unlock Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
public class BankAccountV4 implements BankAccount {
private int balance;
private final Lock lock = new ReentrantLock();
public BankAccountV4(int initialBalance) {
this.balance = initialBalance;
}
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
/*
ReentrantLock 이용하여 lock 을 걸었다.
락을 획득하지 못한 스레드는 ReentrantLock 내부 대기 큐에서 관리된다.
*/
lock.lock();
try {
log("[검증 시작] 출금액: " + amount + ", 잔액: " + balance);
if (balance < amount) {
log("[검증 실패] 출금액: " + amount + ", 잔액: " + balance);
return false;
}
log("[검증 완료] 출금액: " + amount + ", 잔액: " + balance);
sleep(1000); // 출금에 걸리는 시간으로 가정. sleep 을 주석처리 해도 동시성 문제 해결 불가능하다.
balance = balance - amount;
log("[출금 완료] 출금액: " + amount + ", 변경 잔액: " + balance);
} finally {
lock.unlock();
}
log("거래 종료");
return true;
}
@Override
public synchronized int getBalance() {
lock.lock();
try {
return balance;
} finally {
lock.unlock();
}
}
}
- t1 스레드가 먼저 ReentrantLock의 락을 선점했을 때, t2 스레드는 아래와 같이 ReentrantLock 내부 대기 큐에서 관리된다.
![]()
![]()

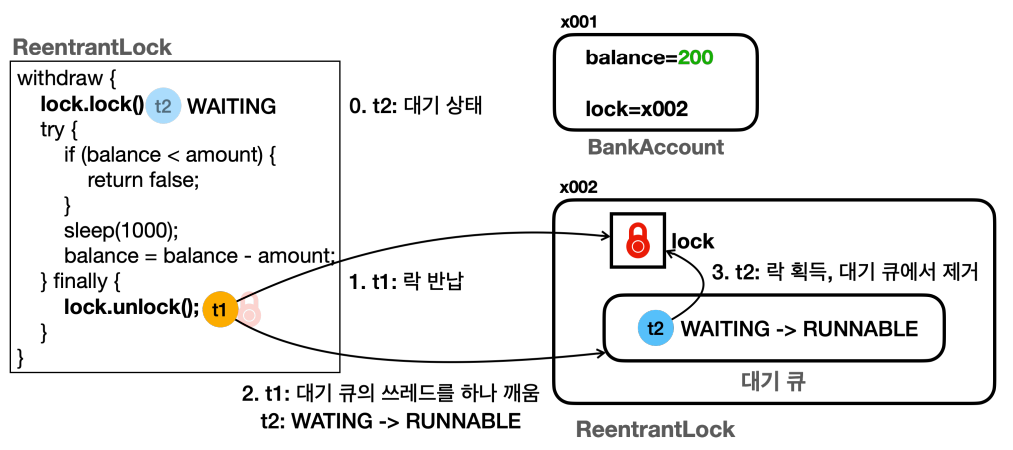
tryLock() Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
public class BankAccountV5 implements BankAccount {
private int balance;
private final Lock lock = new ReentrantLock();
public BankAccountV5(int initialBalance) {
this.balance = initialBalance;
}
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
// 다른 스레드가 락을 선점하여 락을 획득하지 못했다면, 해당 스레드는 종료된다. TERMINATED
if (!lock.tryLock()) {
log("[진입 실패] 이미 처리중인 작업이 있습니다.");
return false;
}
try {
log("[검증 시작] 출금액: " + amount + ", 잔액: " + balance);
if (balance < amount) {
log("[검증 실패] 출금액: " + amount + ", 잔액: " + balance);
return false;
}
log("[검증 완료] 출금액: " + amount + ", 잔액: " + balance);
sleep(1000); // 출금에 걸리는 시간으로 가정. sleep 을 주석처리 해도 동시성 문제 해결 불가능하다.
balance = balance - amount;
log("[출금 완료] 출금액: " + amount + ", 변경 잔액: " + balance);
} finally {
lock.unlock(); // ReentrantLock 이용하여 lock 해제
}
log("거래 종료");
return true;
}
@Override
public synchronized int getBalance() {
lock.lock();
try {
return balance;
} finally {
lock.unlock();
}
}
}
tryLock(시간) Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
public class BankAccountV6 implements BankAccount {
private int balance;
private final Lock lock = new ReentrantLock();
public BankAccountV6(int initialBalance) {
this.balance = initialBalance;
}
@Override
public boolean withdraw(int amount) {
log("거래 시작: " + getClass().getSimpleName());
try {
if (!lock.tryLock(500, TimeUnit.MILLISECONDS)) {
log("[진입 실패] 이미 처리중인 작업이 있습니다.");
return false;
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
try {
log("[검증 시작] 출금액: " + amount + ", 잔액: " + balance);
if (balance < amount) {
log("[검증 실패] 출금액: " + amount + ", 잔액: " + balance);
return false;
}
log("[검증 완료] 출금액: " + amount + ", 잔액: " + balance);
sleep(1000); // 출금에 걸리는 시간으로 가정. sleep 을 주석처리 해도 동시성 문제 해결 불가능하다.
balance = balance - amount;
log("[출금 완료] 출금액: " + amount + ", 변경 잔액: " + balance);
} finally {
lock.unlock(); // ReentrantLock 이용하여 lock 해제
}
log("거래 종료");
return true;
}
@Override
public int getBalance() {
lock.lock();
try {
return balance;
} finally {
lock.unlock();
}
}
}
생산자 소비자
- 생산자(Producer)
- 데이터를 생성하는 역할을 한다.
- e.g. 사용자의 입력을 프린터 큐에 전달하는 스레드
- 소비자(Consumer)
- 생성된 데이터를 사용하는 역할을 한다.
- e.g. 프린터 큐에 전달된 데이터를 받아서 출력하는 스레드
- 버퍼(Buffer)
- 생산자가 생성한 데이터를 일시적으로 저장하는 공간이다. 이 버퍼는 한정된 크기를 가지며, 생산자와 소비자가 이 버퍼를 통해 데이터를 주고받는다.
- e.g. 프린터 큐
- 문제 상황
- 생산자가 너무 바쁠 경우
- 버퍼가 가득 차서 데이터를 더 이상 넣을 수 없어 버퍼에 빈 공간이 생길 때까지 기다린다.
- 소비자가 너무 빠를 경우
- 버퍼가 비어서 더 이상 소비할 데이터가 없을 때 새로운 데이터가 들어올 때까지 기다린다.
- 생산자가 너무 바쁠 경우
- 생산자 소비자 문제(producer-consumer problem)
- 생산자 소비자 문제는, 생산자 스레드와 소비자 스레드가 특정 자원을 함께 생산하고, 소비하면서 발생하는 문제이다.
- 한정된 버퍼 문제(bounded-buffer problem)
- 이 문제는 결국 중간에 있는 버퍼의 크기가 한정되어 있기 때문에 발생한다. 따라서 한정된 버퍼 문제라고도 한다.
Producer, Consumer Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
public class ProducerTask implements Runnable {
private final BoundedQueue boundedQueue;
private final String request;
public ProducerTask(BoundedQueue boundedQueue, String request) {
this.boundedQueue = boundedQueue;
this.request = request;
}
@Override
public void run() {
log("[생산 시도] " + request + " -> " + boundedQueue);
boundedQueue.put(request);
log("[생산 완료] " + request + " -> " + boundedQueue);
}
}
public class ConsumerTask implements Runnable {
private final BoundedQueue boundedQueue;
public ConsumerTask(BoundedQueue boundedQueue) {
this.boundedQueue = boundedQueue;
}
@Override
public void run() {
log("[소비 시도] ? <- " + boundedQueue);
String data = boundedQueue.take();
log("[소비 완료] " + data + " <- " + boundedQueue);
}
}
public class BoundedMain {
public static void main(String[] args) {
// BoundedQueue queue = new BoundedQueueV1(2);
// BoundedQueue queue = new BoundedQueueV2(2);
BoundedQueue queue = new BoundedQueueV3(2);
// producerFirst(queue); // 생산자 먼저
consumerFirst(queue); // 소비자 먼저
//
}
private static void producerFirst(BoundedQueue queue) {
log("== [생산자 먼저 실행] 시작, " + queue.getClass().getSimpleName() + " ==");
List<Thread> threads = new ArrayList<>();
startProducer(queue, threads);
printAllState(queue, threads);
startConsumer(queue, threads);
printAllState(queue, threads);
log("== [생산자 먼저 실행] 종료, " + queue.getClass().getSimpleName() + " ==");
}
private static void consumerFirst(BoundedQueue queue) {
log("== [소비자 먼저 실행] 시작, " + queue.getClass().getSimpleName() + " ==");
List<Thread> threads = new ArrayList<>();
startConsumer(queue, threads);
printAllState(queue, threads);
startProducer(queue, threads);
printAllState(queue, threads);
log("== [소비자 먼저 실행] 종료, " + queue.getClass().getSimpleName() + " ==");
}
private static void startProducer(BoundedQueue queue, List<Thread> threads) {
System.out.println();
log("생산자 시작");
for (int i = 1; i <= 3; i++) {
Thread producer =
new Thread(new ProducerTask(queue, "data" + i), "producer" + i);
threads.add(producer);
producer.start();
sleep(100);
}
}
private static void startConsumer(BoundedQueue queue, List<Thread> threads) {
System.out.println();
log("소비자 시작");
for (int i = 1; i <= 3; i++) {
Thread consumer = new Thread(new ConsumerTask(queue), "consumer" + i);
threads.add(consumer);
consumer.start();
sleep(100);
}
}
private static void printAllState(BoundedQueue queue, List<Thread> threads) {
System.out.println();
log("현재 상태 출력, 큐 데이터: " + queue);
for (Thread thread : threads) {
log(thread.getName() + ": " + thread.getState());
}
}
}
Producer, Consumer Code Version 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public class BoundedQueueV1 implements BoundedQueue {
private final Queue<String> queue = new ArrayDeque<>();
private final int max;
public BoundedQueueV1(int max) {
this.max = max;
}
/**
* private final Queue<String> queue = new ArrayDeque<>();
* 여러 스레드가 접근할 예정이므로 synchronized 를 사용해서
* 한 번에 하나의 스레드만 put() 또는 take() 를 실행할 수 있도록 안전한 임계 영역을 만든다.
*/
@Override
public synchronized void put(String data) {
if (queue.size() == max) {
log("[put] 큐가 가득 참, 버림: " + data);
return;
}
queue.offer(data);
}
@Override
public synchronized String take() {
if (queue.isEmpty()) {
return null;
}
return queue.poll();
}
@Override
public String toString() {
return queue.toString();
}
}
단순한 큐 자료 구조이다. 스레드를 제어할 수 없기 때문에, 버퍼가 가득 차거나, 버퍼에 데이터가 없는 한정된 버퍼 상황에서 문제가 발생한다.
버퍼가 가득 찬 경우: 생산자의 데이터를 버린다.
버퍼에 데이터가 없는 경우: 소비자는 데이터를 획득할 수 없다. ( null )
Producer, Consumer Code Version 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
public class BoundedQueueV2 implements BoundedQueue {
private final Queue<String> queue = new ArrayDeque<>();
private final int max;
public BoundedQueueV2(int max) {
this.max = max;
}
/**
* private final Queue<String> queue = new ArrayDeque<>();
* 여러 스레드가 접근할 예정이므로 synchronized 를 사용해서
* 한 번에 하나의 스레드만 put() 또는 take() 를 실행할 수 있도록 안전한 임계 영역을 만든다.
*/
@Override
public synchronized void put(String data) {
while (queue.size() == max) {
log("[put] 큐가 가득 참, 생산자 대기");
sleep(1000);
}
queue.offer(data);
}
@Override
public synchronized String take() {
while (queue.isEmpty()) {
log("[take] 큐에 데이터가 없음, 소비자 대기");
sleep(1000);
}
return queue.poll();
}
@Override
public String toString() {
return queue.toString();
}
}
앞서 발생한 문제를 해결하기 위해 반복문을 사용해서 스레드를 대기하는 방법을 적용했다. 하지만 synchronized 임계 영역 안에서 락을 들고 대기하기 때문에, 다른 스레드가 임계 영역에 접근할 수 없는 문제가 발생했다. 결과적으로 나머지 스레드는 모두 BLOCKED 상태가 되고, 자바 스레드 세상이 멈추는 심각한 문제가 발생했다.
Producer, Consumer Code Version 3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
public class BoundedQueueV3 implements BoundedQueue {
private final Queue<String> queue = new ArrayDeque<>();
private final int max;
public BoundedQueueV3(int max) {
this.max = max;
}
/**
* private final Queue<String> queue = new ArrayDeque<>();
* 여러 스레드가 접근할 예정이므로 synchronized 를 사용해서
* 한 번에 하나의 스레드만 put() 또는 take() 를 실행할 수 있도록 안전한 임계 영역을 만든다.
*/
@Override
public synchronized void put(String data) {
while (queue.size() == max) {
log("[put] 큐가 가득 참, 생산자 대기");
try {
// RUNNABLE -> WAITING: 락을 반납하고 대기
// wait(): 해당 스레드는 스레드 대기 집합에서 대기한다.
wait();
log("[put] 생산자 깨어남");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
queue.offer(data);
log("[put] 생산자 데이터 저장, notify() 호출");
// 대기 스레드, WAIT -> BLOCKED
// notify(): 스레드 대기 집합에서 대기하는 스레드 중 하나를 깨운다.
// notify();
// 모든 대기 스레드, WAIT -> BLOCKED
notifyAll();
}
@Override
public synchronized String take() {
while (queue.isEmpty()) {
log("[take] 큐에 데이터가 없음, 소비자 대기");
try {
// RUNNABLE -> WAITING: 락을 반납하고 대기
wait();
log("[take] 소비자 깨어남");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
String data = queue.poll();
log("[take] 소비자 데이터 획득, notify() 호출");
// 대기 스레드, WAIT -> BLOCKED
notify();
// 모든 대기 스레드, WAIT -> BLOCKED
notifyAll();
return data;
}
@Override
public String toString() {
return queue.toString();
}
}
synchronized 와 함께 사용할 수 있는 wait() , notify() , notifyAll() 을 사용해서 문제를 해결했다. wait() 를 사용하면 스레드가 대기할 때, 락을 반납하고 대기한다. 이후에 notify() 를 호출하면 스레드가 깨어나면서 락 획득을 시도한다. 이때 락을 획득하면 RUNNABLE 상태가 되고, 락을 획득하지 못하면 락 획득을 대기하는 BLOCKED 상태가 된다.
이렇게 해서 스레드를 제어하는 큐 자료 구조를 만들 수 있었다. 생산자 스레드는 버퍼가 가득차면 버퍼에 여유가 생길 때 까지 대기한다. 소비자 스레드는 버퍼에 데이터가 없으면 버퍼에 데이터가 들어올 때 까지 대기한다.
이 방식의 단점은 스레드가 대기하는 대기 집합이 하나이기 때문에, 원하는 스레드를 선택해서 깨울 수 없다는 문제가 있었다. 예를 들어서 생산자는 데이터를 생산한 다음 대기하는 소비자를 깨워야 하는데, 대기하는 생산자를 깨울 수 있다. 따라서 비효율이 발생한다. 물론 이렇게 해도 비효율이 있을 뿐 로직은 모두 정상 작동한다.
notify() 는 원하는 목표를 지정할 수 없었다. 물론 notifyAll() 을 사용할 수 있지만, 원하지 않는 모든 스레드까지 모두 깨어난다. 이런 문제를 해결하려면 어떻게 해야할까??
Producer, Consumer Code Version 4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
public class BoundedQueueV4 implements BoundedQueue {
/*
lock.newCondition(): 스레드 대기 공간 생성
synchronized 대신에 Lock lock = new ReentrantLock 을 사용
참고
Object.wait() 에서 사용한 스레드 대기 공간은 모든 객체 인스턴스가 내부에 기본으로 가지고 있다.
Lock(ReentrantLock) 을 사용하는 경우 이렇게 스레드 대기 공간을 직접 만들어서 사용해야 한다.
*/
private final Lock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
private final Queue<String> queue = new ArrayDeque<>();
private final int max;
public BoundedQueueV4(int max) {
this.max = max;
}
/*
condition.await()
Object.wait() 와 유사한 기능이다.
지정한 condition 에 현재 스레드를 대기( WAITING ) 상태로 보관한다.
이 때 ReentrantLock 에서 획득한 락을 반납하고 대기 상태로 condition 에 보관된다.
condition.signal()
Object.notify() 와 유사한 기능이다.
지정한 condition 에서 대기중인 스레드를 하나 깨운다.
깨어난 스레드는 condition 에서 빠져나온다.
*/
@Override
public void put(String data) {
lock.lock();
try {
while (queue.size() == max) {
log("[put] 큐가 가득 참, 생산자 대기");
try {
condition.await();
log("[put] 생산자 깨어남");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
queue.offer(data);
log("[put] 생산자 데이터 저장, signal() 호출");
condition.signal();
} finally {
lock.unlock();
}
}
@Override
public String take() {
lock.lock();
try {
while (queue.isEmpty()) {
log("[take] 큐에 데이터가 없음, 소비자 대기");
try {
condition.await();
log("[take] 소비자 깨어남");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
String data = queue.poll();
log("[take] 소비자 데이터 획득, signal() 호출");
condition.signal();
return data;
} finally {
lock.unlock();
}
}
@Override
public String toString() {
return queue.toString();
}
}
synchronized 와 wait() , notify() 를 사용해서 구현하면 스레드 대기 집합이 하나라는 단점이 있다. 이 단점을 극복하려면 스레드 대기 집합을 생산자 전용과 소비자 전용으로 나누어야 한다. 이렇게 하려면 Lock(ReentrantLock) 을 사용해야 한다.
여기서는 단순히 synchronized 와 wait() , notify() 를 사용해서 구현한 코드를 Lock(ReentrantLock) 를 사용하도록 변경했다. 다음으로 넘어가기 위한 중간 단계의 코드이다.
Producer, Consumer Code Version 5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
/**
* 생산자용, 소비자용 대기 집합을 서로 나누어 분리하여 비효율 문제를 해결한다.
* lock.newCondition() 을 두 번 호출해서 ReentrantLock 을 사용하는 스레드 대기 공간을 2개 만든다.
*
* 핵심: 생산자는 소비자를 깨우고, 소비자는 생산자를 깨운다.
*/
public class BoundedQueueV5 implements BoundedQueue {
private final Lock lock = new ReentrantLock();
private final Condition producerCondition = lock.newCondition();
private final Condition consumerCondition = lock.newCondition();
private final Queue<String> queue = new ArrayDeque<>();
private final int max;
public BoundedQueueV5(int max) {
this.max = max;
}
@Override
public void put(String data) {
lock.lock();
try {
while (queue.size() == max) {
log("[put] 큐가 가득 참, 생산자 대기");
try {
producerCondition.await();
log("[put] 생산자 깨어남");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
queue.offer(data);
log("[put] 생산자 데이터 저장, signal() 호출");
consumerCondition.signal();
} finally {
lock.unlock();
}
}
@Override
public String take() {
lock.lock();
try {
while (queue.isEmpty()) {
log("[take] 큐에 데이터가 없음, 소비자 대기");
try {
consumerCondition.await();
log("[take] 소비자 깨어남");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
String data = queue.poll();
log("[take] 소비자 데이터 획득, signal() 호출");
producerCondition.signal();
return data;
} finally {
lock.unlock();
}
}
@Override
public String toString() {
return queue.toString();
}
}
Lock(ReentrantLock) 는 Condition 이라는 스레드 대기 공간을 제공한다. 이 스레드 대기 공간을 원하는 만큼 따로 만들 수 있다.
productCond : 생산자 스레드를 위한 전용 대기 공간
consumerCond : 소비자 스레드를 위한 전용 대기 공간
덕분에 생산자가 데이터를 생산하고 나면 consumerCond.signal() 메서드를 통해 소비자 전용 대기 공간에 이 사실을 알릴 수 있다. 반대로 소비자가 데이터를 소비하고 나면 productCond.signal() 을 통해 생산자 전용 대기 공간에 이 사실을 알릴 수 있다.
이렇게 스레드 대기 공간을 나누어서 앞서 synchronized , wait() , notify() 를 사용한 방식에서 발생한 비효율 문제를 깔끔하게 해결할 수 있었다.
- Object.notify() vs Condition.signal()
- Object.notify()
- 대기 중인 스레드 중 임의의 하나를 선택해서 깨운다. 스레드가 깨어나는 순서는 정의되어 있지 않으며, JVM 구현에 따라 다르다. 보통은 먼저 들어온 스레드가 먼저 수행되지만 구현에 따라 다를 수 있다. synchronized 블록 내에서 모니터 락을 가지고 있는 스레드가 호출해야 한다.
- Condition.signal()
- 대기 중인 스레드 중 하나를 깨우며, 일반적으로는 FIFO 순서로 깨운다. 이 부분은 자바 버전과 구현에 따라 달라질 수 있지만, 보통 Condition 의 구현은 Queue 구조를 사용하기 때문에 FIFO 순서로 깨운다. ReentrantLock 을 가지고 있는 스레드가 호출해야 한다.
- Object.notify()
- 정리
- 자바의 모든 객체 인스턴스는 멀티스레드와 임계 영역을 다루기 위해 내부에 3가지 기본 요소를 가진다.
- 모니터 락
- 락 대기 집합(모니터 락 대기 집합)
- 스레드 대기 집합
여기서 락 대기 집합이 1차 대기소이고, 스레드 대기 집합이 2차 대기소라 생각하면 된다. 2차 대기소에 들어간 스레드는 2차, 1차 대기소를 모두 빠져나와야 임계 영역을 수행할 수 있다.
- synchronized 를 사용한 임계 영역에 들어가려면 모니터 락이 필요하다.
- 모니터 락이 없으면 락 대기 집합에 들어가서 BLOCKED 상태로 락을 기다린다.
- 모니터 락을 반납하면 락 대기 잡합에 있는 스레드 중 하나가 락을 획득하고 BLOCKED -> RUNNABLE 상태가 된다.
- wait() 를 호출해서 스레드 대기 집합에 들어가기 위해서는 모니터 락이 필요하다.
- 스레드 대기 집합에 들어가면 모니터 락을 반납한다.
- 스레드가 notify() 를 호출하면 스레드 대기 집합에 있는 스레드 중 하나가 스레드 대기 집합을 빠져나온다. 그리고 모니터 락 획득을 시도한다.
- 모니터 락을 획득하면 임계 영역을 수행한다.
- 모니터 락을 획득하지 못하면 락 대기 집합에 들어가서 BLOCKED 상태로 락을 기다린다.
- 대기1: 모니터 락 획득 대기
- 자바 객체 내부의 락 대기 집합(모니터 락 대기 집합)에서 관리
- BLOCKED 상태로 락 획득 대기
- synchronized 를 시작할 때 락이 없으면 대기
- 다른 스레드가 synchronized 를 빠져나갈 때 락을 획득 시도, 락을 획득하면 락 대기 집합을 빠져나감
- 대기2: wait() 대기
- wait() 를 호출 했을 때 자바 객체 내부의 스레드 대기 집합에서 관리
- WAITING 상태로 대기
- 다른 스레드가 notify() 를 호출 했을 때 스레드 대기 집합을 빠져나감
- 대기1: ReentrantLock 락 획득 대기
- ReentrantLock 의 대기 큐에서 관리
- WAITING 상태로 락 획득 대기
- lock.lock() 을 호출 했을 때 락이 없으면 대기
- 다른 스레드가 lock.unlock() 을 호출 했을 때 대기가 풀리며 락 획득 시도, 락을 획득하면 대기 큐를 빠져나감
- 대기2: await() 대기
- condition.await() 를 호출 했을 때, condition 객체의 스레드 대기 공간에서 관리
- WAITING 상대로 대기
- 다른 스레드가 condition.signal() 을 호출 했을 때 condition 객체의 스레드 대기 공간에서 빠져나감
BlockingQueue
- BoundedQueue 를 스레드 관점에서 보면 큐가 특정 조건이 만족될 때까지 스레드의 작업을 차단(blocking)한다.
- 데이터 추가 차단: 큐가 가득 차면 데이터 추가 작업( put() )을 시도하는 스레드는 공간이 생길 때까지 차단된다.
데이터 획득 차단: 큐가 비어 있으면 획득 작업( take() )을 시도하는 스레드는 큐에 데이터가 들어올 때까지 차단된다.
- BlockingQueue 인터페이스의 대표적인 구현체
- ArrayBlockingQueue
- 배열 기반으로 구현되어 있고, 버퍼의 크기가 고정되어 있다.
- LinkedBlockingQueue
- 링크 기반으로 구현되어 있고, 버퍼의 크기를 고정할 수도, 또는 무한하게 사용할 수도 있다.
- ArrayBlockingQueue
- 큐가 가득 찼을 때 생각할 수 있는 선택지 4가지
- 예외를 던진다. 예외를 받아서 처리한다.
- 대기하지 않는다. 즉시 false 를 반환한다.
- 대기한다.
- 특정 시간 만큼만 대기한다.
- Throws Exception - 대기시 예외
- add(e): 지정된 요소를 큐에 추가하며, 큐가 가득 차면 IllegalStateException 예외를 던진다.
- remove(): 큐에서 요소를 제거하며 반환한다. 큐가 비어 있으면 NoSuchElementException 예외를 던진다.
- element(): 큐의 머리 요소를 반환하지만, 요소를 큐에서 제거하지 않는다. 큐가 비어 있으면 NoSuchElementException 예외를 던진다.
- Special Value - 대기시 즉시 반환
- offer(e): 지정된 요소를 큐에 추가하려고 시도하며, 큐가 가득 차면 false 를 반환한다.
- poll(): 큐에서 요소를 제거하고 반환한다. 큐가 비어 있으면 null 을 반환한다.
- peek(): 큐의 머리 요소를 반환하지만, 요소를 큐에서 제거하지 않는다. 큐가 비어 있으면 null 을 반환한다.
- Blocks - 대기
- put(e): 지정된 요소를 큐에 추가할 때까지 대기한다. 큐가 가득 차면 공간이 생길 때까지 대기한다.
- take(): 큐에서 요소를 제거하고 반환한다. 큐가 비어 있으면 요소가 준비될 때까지 대기한다.
- Examine (관찰): 해당 사항 없음.
- Times Out - 시간 대기
- offer(e, time, unit): 지정된 요소를 큐에 추가하려고 시도하며, 지정된 시간 동안 큐가 비워지기를 기다리다가 시간이 초과되면 false 를 반환한다.
- poll(time, unit): 큐에서 요소를 제거하고 반환한다. 큐에 요소가 없다면 지정된 시간 동안 요소가 준비되기를 기다리다가 시간이 초과되면 null 을 반환한다.
- Examine (관찰): 해당 사항 없음.
BlockingQueue Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class BoundedQueueV6_1 implements BoundedQueue {
private BlockingQueue<String> queue;
public BoundedQueueV6_1(int max) {
queue = new ArrayBlockingQueue<>(max);
}
@Override
public void put(String data) {
try {
queue.put(data);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Override
public String take() {
try {
return queue.take();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Override
public String toString() {
return queue.toString();
}
}
BlockingQueue Code 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class BoundedQueueV6_2 implements BoundedQueue {
/*
offer(), poll()
두 메서드는 스레드가 대기하지 않는다.
offer(data) 는 성공하면 true 를 반환하고, 버퍼가 가득 차면 즉시 false 를 반환한다.
poll() 버퍼에 데이터가 없으면 즉시 null 을 반환한다.
*/
private BlockingQueue<String> queue;
public BoundedQueueV6_2(int max) {
queue = new ArrayBlockingQueue<>(max);
}
@Override
public void put(String data) {
boolean result = queue.offer(data);
log("저장 시도 결과 = " + result);
}
@Override
public String take() {
return queue.poll();
}
@Override
public String toString() {
return queue.toString();
}
}
BlockingQueue Code 3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
public class BoundedQueueV6_3 implements BoundedQueue {
/*
offer(data, 시간)
성공하면 true 를 반환하고, 버퍼가 가득 차서 스레드가 대기해야 하는 상황이면,
지정한 시간까지 대기한다. 대기 시간을 지나면 false 를 반환한다.
여기서는 확인을 목적으로 1 나노초( NANOSECONDS )로 설정했다.
poll(시간)
버퍼에 데이터가 없어서 스레드가 대기해야 하는 상황이면, 지정한 시간까지 대기한다.
대기 시간을 지나면 null 을 반환한다.
여기서는 2초( SECONDS )로 설정했다.
*/
private BlockingQueue<String> queue;
public BoundedQueueV6_3(int max) {
queue = new ArrayBlockingQueue<>(max);
}
@Override
public void put(String data) {
try {
// 대기 시간 설정 가능
boolean result = queue.offer(data, 1, TimeUnit.NANOSECONDS);
log("저장 시도 결과 = " + result);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Override
public String take() {
try {
// 대기 시간 설정 가능
return queue.poll(2, TimeUnit.SECONDS);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Override
public String toString() {
return queue.toString();
}
}
BlockingQueue Code 4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public class BoundedQueueV6_4 implements BoundedQueue {
/*
add(data)
성공하면 true 를 반환하고, 버퍼가 가득 차면 즉시 예외가 발생한다.
java.lang.IllegalStateException: Queue full
remove()
버퍼에 데이터가 없으면, 즉시 예외가 발생한다.
java.util.NoSuchElementException
*/
private BlockingQueue<String> queue;
public BoundedQueueV6_4(int max) {
queue = new ArrayBlockingQueue<>(max);
}
@Override
public void put(String data) {
queue.add(data); // java.lang.IllegalStateException: Queue full
}
@Override
public String take() {
return queue.remove(); // java.util.NoSuchElementException
}
@Override
public String toString() {
return queue.toString();
}
}
CAS-동기화와 원자적 연산
- 원자적 연산(atomic operation)
- 해당 연산이 더 이상 나눌 수 없는 단위로 수행된다.
- 중단되지 않고 다른 연산과 간섭 없이 완전히 실행되거나 전혀 실행되지 않는다.
- 멀티스레드 상황에서 다른 스레드의 간섭 없이 안전하게 처리되는 연산이다.
- e.g.
- i = 1 (원자적 연산 o)
- i = i + 1 (원자적 연산 x)
- 원자적 연산은 멀티스레드 상황에서 문제가 없지만, 원자적 연산이 아닌 경우에는 synchronized 블럭이나 Lock 등을 사용해서 안전한 임계영역을 만들어야 한다.
- CAS(Compare-And-Swap, Compare-And-Set)
- 락을 걸지 않고 원자적인 연산을 수행한다.(락 프리 기법)
- 락을 사용하는 방식은 직관적이지만 상대적으로 무거운 방식인 반면에 CAS 연산은 락을 완전히 대체하는 것은 아니고 작은 단위의 일부 영역에 적용할 수 있다.
- 기본적으로 락을 사용하고 특별한 경우에 CAS를 적용한다고 보면 된다.
- CAS(Compare-And-Swap)와 락(Lock) 방식의 비교
- 락(Lock) 방식
- 비관적(pessimistic) 접근법
- 데이터에 접근하기 전에 항상 락을 획득
- 다른 스레드의 접근을 막음
- “다른 스레드가 방해할 것이다”라고 가정
- CAS(Compare-And-Swap) 방식
- 낙관적(optimistic) 접근법
- 락을 사용하지 않고 데이터에 바로 접근
- 충돌이 발생하면 그때 재시도
- “대부분의 경우 충돌이 없을 것이다”라고 가정
- 락(Lock) 방식
SpinLock Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class SpinLockBad {
private volatile boolean lock = false;
public void lock() {
log("락 획득 시도");
while(true) {
if (!lock) { // 1. 락 사용 여부 확인
sleep(100); // 문제 상황 확인용, 스레드 대기
lock = true; // 2. 락의 값 변경
break; // while 탈출
} else {
// 락을 획득할 때 까지 스핀 대기(바쁜 대기) 한다.
log("락 획득 실패 - 스핀 대기");
}
}
log("락 획득 완료");
}
public void unlock() {
lock = false;
log("락 반납 완료");
}
}
SpinLock Code 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class SpinLock {
private final AtomicBoolean lock = new AtomicBoolean(false);
public void lock() {
log("락 획득 시도");
while (!lock.compareAndSet(false, true)) {
// 락을 획득할 때까지 스핀 대기(바쁜 대기)한다.
log("락 획득 실패 - 스핀 대기");
}
log("락 획득 완료");
}
public void unlock() {
lock.set(false);
log("락 반납 완료");
}
}
SpinLock Code 3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
public class SpinLockMain {
public static void main(String[] args) {
// spinLock spinLock = new spinLock();
SpinLock spinLock = new SpinLock();
Runnable task = new Runnable() {
@Override
public void run() {
spinLock.lock();
try {
// critical section
log("business logic");
// sleep(1); // 오래 걸리는 로직에서 스핀 락 사용 x
/*
- 락을 기다리는 스레드가 block, waiting 상태에 빠지지 않지만
runnable 상태로 락을 획득할 때까지 while 문을 반복하는 문제 존재.
- cpu 자원 낭비: 락을 기다리는 스레드가 cpu 를 계속 사용하면서 대기
*/
} finally {
spinLock.unlock();
}
}
};
Thread t1 = new Thread(task, "Thread-1");
Thread t2 = new Thread(task, "Thread-2");
t1.start();
t2.start();
}
}
⭐ 정리
- 일반적으로 동기화 락을 사용하고, 아주 특별한 경우에 한정해서 CAS를 사용해서 최적화해야 한다.
- CAS 사용
- 숫자 값의 증가, 자료 구조의 데이터 추가, 삭제와 같이 CPU 사이클이 금방 끝나지만 안전한 임계 영역, 또는 원자적인 연산이 필요한 경우에 사용
- 동기화 Lock 사용 / 스레드 대기
- 데이터베이스를 기다린다거나, 다른 서버의 요청을 기다리는 것 처럼 오래 기다리는 작업할 때 사용
동시성 컬렉션
- 스레드 세이프(Thread Safe)
- 여러 스레드가 동시에 접근해도 괜찮은 경우
- 컬렉션 프레임워크가 제공하는 대부분의 연산은 원자적인 연산이 아니다.
- synchronized, Lock 등을 통해 안전한 임계영역을 만들어 문제 해결
- 프록시
- 대신 처리해주는 자
- 기존의 컬렉션 프레임워크가 제공하는 코드를 그대로 사용하면서 밀티스레드 상황에 동기화가 필요할 때만 synchronized 기능을 추가
- 프록시 패턴
- 정의
- 객체지향 디자인 패턴 중 하나
- 어떤 객체에 대한 접근을 제어하기 위해 그 객체의 대리인 또는 인터페이스 역할을 하는 객체를 제공하는 패턴
- 실제 객체에 대한 참조를 유지하면서, 그 객체에 접근하거나 행동을 수행하기 전에 추가적인 처리를 할 수 있게한다.
- 목적
- 접근 제어: 실제 객체에 대한 접근을 제한 및 통제 가능
- 성능 향상: 실제 객체의 생성을 지여니키거나 캐싱하여 성능을 최적화
- 부가 기능 제공: 실제 객체에 추가적인 기능(로깅, 인증, 동기화 등)을 투명하게 제공
- 정의
Proxy Pattern Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class SyncProxyList implements SimpleList {
private SimpleList target;
public SyncProxyList(SimpleList target) {
this.target = target;
}
@Override
public synchronized void add(Object e) {
target.add(e);
}
@Override
public synchronized Object get(int index) {
return target.get(index);
}
@Override
public synchronized int size() {
return target.size();
}
@Override
public synchronized String toString() {
return target.toString() + " by " + this.getClass().getSimpleName();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
public class SimpleListMainV2 {
public static void main(String[] args) throws InterruptedException {
// test(new BasicList());
// test(new SyncList());
test(new SyncProxyList(new BasicList()));
}
private static void test(SimpleList list) throws InterruptedException {
log(list.getClass().getSimpleName());
// A를 리스트에 저장하는 코드
Runnable addA = new Runnable() {
@Override
public void run() {
list.add("A");
log("Thread-1: list.add(A)");
}
};
// B를 리스트에 저장하는 코드
Runnable addB = new Runnable() {
@Override
public void run() {
list.add("B");
log("Thread-2: list.add(B)");
}
};
Thread thread1 = new Thread(addA, "Thread-1");
Thread thread2 = new Thread(addB, "Thread-2");
thread1.start();
thread2.start();
thread1.join();
thread2.join();
log(list);
}
}
자바 동시성 컬렉션의 종류
- List
- CopyOnWriteArrayList: ArrayList 대안
- Set
- CopyOnWriteArraySet: HashSet 대안
- ConcurrentSkipListSet: TreeSet 대안(정렬된 순서 유지, Comparator 사용 가능)
- Map
- ConcurrentHashMap: HashMap 대안
- ConcurrentSkipListMap: TreeMap 대안(정렬된 순서 유지, Comparator 사용 가능)
- Queue
- ConcurrentLinkedQueue: 동시성 큐, 비 차단(non-blocking) 큐
- Deque
- ConcurrnetLinkedDeque: 동시성 데크, 비 차단(non-blocking) 큐
스레드 차단 블로킹 큐
- BlockingQueue
- ArrayBlockingQueue
- 크기가 고정된 블로킹 큐
- 공정(fair) 모드를 사용할 수 있다. 공정(fair) 모드를 사용하면 성능이 저하될 수 있다.
- LinkedBlockingQueue
- 크기가 무한하거나 고정된 블로킹 큐
- PriorityBlockingQueue
- 우선순위가 높은 요소를 먼저 처리하는 블로킹 큐
- SynchronousQueue
- 데이터를 저장하지 않는 블로킹 큐로, 생산자가 데이터를 추가하면 소비자가 그 데이터를 받을 때까지 대기한다. 생산자-소비자 간의 직접적인 핸드오프(hand-off) 메커니즘을 제공한다. 쉽게 이야기해서 중간에 큐 없이 생산자, 소비자가 직접 거래한다.
- DelayQueue
- 지연된 요소를 처리하는 블로킹 큐로, 각 요소는 지정된 지연 시간이 지난 후에야 소비될 수 있다. 일정 시간이 지난 후 작업을 처리해야 하는 스케줄링 작업에 사용된다.
- ArrayBlockingQueue
⭐ 정리
- 단일 스레드: 일반 컬렉션 사용
- 멀티 스레드: 동시성 컬렉션 사용
스레드 풀과 Executor 프레임워크
- 스레드를 직접 사용할 때의 문제점
- 스레드 생성 시간으로 인한 성능 문제
- 메모리 할당
- 운영체제 자원 사용
- 운영체제 스케줄러 설정
- 스레드 관리 문제
- Runnable 인터페이스의 불편함
- run() 메소드는 반환 값이 없어 실행 결과를 직접 받을 수 없다.
- 메소드 내부에서 처리해야하는 체크 예외 처리 불가능
- 스레드 생성 시간으로 인한 성능 문제
- 스레드 풀
- 스레드 문제점 1번, 2번 해결
Executor Framework
- 스레드 풀, 스레드 관리, Runnable 의 문제점은 물론이고, 생산자 소비자 문제까지 한방에 해결해주는 자바 멀티스레드 최고의 도구
1
2
3
4
5
6
7
8
9
10
11
12
// Executor Interface
public interface Executor {
void execute(Runnable command);
}
// ExecutorService Interface
public interface ExecutorService extends Executor, AutoCloseable {
<T> Future<T> submit(Callable<T> task);
@Override
default void close(){...}
...
}
ThreadPoolExecutor
- ExecutorService 인터페이스의 기본 구현체
ThreadPoolExecutor를 활용한 로그 출력
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
public static void printState(ExecutorService executorService) {
if (executorService instanceof ThreadPoolExecutor poolExecutor) {
int poolSize = poolExecutor.getPoolSize();
int activeCount = poolExecutor.getActiveCount();
int queuedTasks = poolExecutor.getQueue().size();
long completedTask = poolExecutor.getCompletedTaskCount();
log("[poolSize=" + poolSize + ", activeCount=" + activeCount + ", queuedTasks=" + queuedTasks + ", completedTasks=" + completedTask + "]");
/*
poolSize: 풀에서 관리되는 스레드 숫자
activeCount: 작업을 수행하는 스레드 숫자
queuedTasks: 큐에서 대기중인 작업의 숫자
completedTask: 완료된 작업의 숫자
*/
} else {
log(executorService);
}
}
public class RunnableTask implements Runnable {
private final String name;
private int sleepMs = 1000;
public RunnableTask(String name) {
this.name = name;
}
public RunnableTask(String name, int sleepMs) {
this.name = name;
this.sleepMs = sleepMs;
}
@Override
public void run() {
log(name + " 시작");
sleep(sleepMs);
log(name + " 완료");
}
}
public class ExecutorBasicMain {
public static void main(String[] args) {
ExecutorService executorService =
new ThreadPoolExecutor(2, 2, 0, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());
/*
corePoolSize:
스레드 풀에서 관리되는 기본 스레드의 수
maximumPoolSize:
스레드 풀에서 관리되는 최대 스레드 수
keepAliveTime, TimeUnit unit:
기본 스레드 수를 초과해서 만들어진 스레드가 생존할 수 있는 대기 시간이다.
이 시간 동안 처리할 작업이 없다면 초과 스레드는 제거된다.
BlockingQueue workQueue:
작업을 보관할 블로킹 큐
*/
log("== 초기 상태 ==");
printState(executorService);
executorService.execute(new RunnableTask("taskA"));
executorService.execute(new RunnableTask("taskB"));
executorService.execute(new RunnableTask("taskC"));
executorService.execute(new RunnableTask("taskD"));
log("== 작업 수행 중 ==");
printState(executorService);
sleep(3000);
log("== 작업 수행 완료 ==");
printState(executorService);
executorService.close();
log("== shutdown 완료 ==");
printState(executorService);
/*
09:55:21.464 [ main] == 초기 상태 ==
09:55:21.495 [ main] [poolSize=0, activeCount=0, queuedTasks=0, completedTasks=0]
09:55:21.511 [ main] == 작업 수행 중 ==
09:55:21.511 [ main] [poolSize=2, activeCount=2, queuedTasks=2, completedTasks=0]
09:55:21.511 [pool-1-thread-1] taskA 시작
09:55:21.511 [pool-1-thread-2] taskB 시작
09:55:22.521 [pool-1-thread-1] taskA 완료
09:55:22.521 [pool-1-thread-2] taskB 완료
09:55:22.522 [pool-1-thread-1] taskC 시작
09:55:22.523 [pool-1-thread-2] taskD 시작
09:55:23.535 [pool-1-thread-1] taskC 완료
09:55:23.535 [pool-1-thread-2] taskD 완료
09:55:24.520 [ main] == 작업 수행 완료 ==
09:55:24.521 [ main] [poolSize=2, activeCount=0, queuedTasks=0, completedTasks=4]
09:55:24.522 [ main] == shutdown 완료 ==
09:55:24.523 [ main] [poolSize=0, activeCount=0, queuedTasks=0, completedTasks=4]
*/
}
}
Callable Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
public class CallableMainV2 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(1);
log("submit() 호출");
Future<Integer> future = es.submit(new MyCallable());
log("future 즉시 반환, future = " + future);
log("future.get() [블로킹] 메서드 호출 시작 -> main 스레드 WAITING");
Integer result = future.get(); // 블로킹: 작업의 결과를 받을 때까지 요청 스레드 대기
log("future.get() [블로킹] 메서드 호출 완료 -> , main 스레드 RUNNABLE");
log("result value = " + result);
log("future 완료, future = " + future);
es.close();
/*
10:44:44.750 [ main] submit() 호출
10:44:44.765 [pool-1-thread-1] Callable 시작
10:44:44.765 [ main] future 즉시 반환, future = java.util.concurrent.FutureTask@6576fe71[Not completed, task = thread.executor.future.CallableMainV2$MyCallable@7eda2dbb]
10:44:44.765 [ main] future.get() [블로킹] 메서드 호출 시작 -> main 스레드 WAITING
10:44:46.775 [pool-1-thread-1] create value = 0
10:44:46.776 [pool-1-thread-1] Callable 완료
10:44:46.777 [ main] future.get() [블로킹] 메서드 호출 완료 -> , main 스레드 RUNNABLE
10:44:46.778 [ main] result value = 0
10:44:46.779 [ main] future 완료, future = java.util.concurrent.FutureTask@6576fe71[Completed normally]
*/
}
static class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
log("Callable 시작");
sleep(2000);
int value = new Random().nextInt(10);
log("create value = " + value);
log("Callable 완료");
return value;
}
}
}
스레드를 생성하거나, join() 으로 스레드를 제어할 필요 없음
Future는 전달한 작업의 미래 결과를 담고 있다.
요청 스레드가 future.get() 을 호출하면 Future 가 완료 상태가 될 때 까지 대기한다. 이때 요청 스레드의 상태는 RUNNABLE WAITING 이 된다. 이처럼 스레드가 어떤 결과를 얻기 위해 대기하는 것을 블로킹(Blocking)이라 한다.
future의 적절한 활용 예시
1
2
3
4
5
6
7
8
9
10
11
// future 적절한 예: 실행시간 2초
Future<Integer> future1 = es.submit(task1); // non-blocking
Future<Integer> future2 = es.submit(task2); // non-blocking
Integer sum1 = future1.get(); // blocking, 2초 대기
Integer sum2 = future2.get(); // blocking, 즉시 반환
// future 부적절한 예: 실행시간 4초
Future<Integer> future1 = es.submit(task1); // non-blocking
Integer sum1 = future1.get(); // blocking, 2초 대기
Future<Integer> future2 = es.submit(task2); // non-blocking
Integer sum2 = future2.get(); // blocking, 2초 대기
submit(): 작업을 비동기적으로 실행한다.
get(): 작업이 완료될 때까지 기다리며 결과를 반환한다.
⭐ 정리
Callable은 Runnable 인터페이스와는 다르게, 반환값이 존재하고 예외처리 가능하다.
Future
- 작업의 미래 결과를 받을 수 있는 객체
- submit() 호출시 future 는 즉시 반환되어 스레드는 요청 대기하지 않고(블로킹 x), 다른 작업을 수행할 수 있다.
Future.cancel()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
public class FutureCancelMain {
private static boolean mayInterruptIfRunning = true;
// private static boolean mayInterruptIfRunning = false;
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(1);
Future<String> future = es.submit(new MyTask());
log("Future.state: " + future.state()); // RUNNING
// 일정 시간 후 취소 시도
sleep(3000);
// cancel() 호출
log("future.cancel(" + mayInterruptIfRunning +") 호출");
boolean cancelResult1 = future.cancel(mayInterruptIfRunning);
log("Future.state: " + future.state()); // CANCELLED
log("cancel(" + mayInterruptIfRunning + ") result: " + cancelResult1); // true
// 결과 확인
try {
log("Future result: " + future.get());
} catch (CancellationException e) {
log("Future는 이미 취소 되었습니다.");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
// Executor 종료
es.close();
}
static class MyTask implements Callable<String> {
@Override
public String call() throws Exception {
try {
for (int i = 0; i < 10; i++) {
log("작업 중: " + i);
Thread.sleep(1000);
}
} catch (InterruptedException e) {
log(" 인터럽트 발생");
return "Interrupted";
}
return "Completed";
}
}
}
/*
11:07:29.463 [pool-1-thread-1] 작업 중: 0
11:07:29.463 [ main] Future.state: RUNNING
11:07:30.478 [pool-1-thread-1] 작업 중: 1
11:07:31.487 [pool-1-thread-1] 작업 중: 2
11:07:32.468 [ main] future.cancel(false) 호출
11:07:32.468 [ main] Future.state: CANCELLED
11:07:32.476 [ main] cancel(false) result: true
11:07:32.476 [ main] Future는 이미 취소 되었습니다.
11:07:32.500 [pool-1-thread-1] 작업 중: 3
11:07:33.505 [pool-1-thread-1] 작업 중: 4
11:07:34.513 [pool-1-thread-1] 작업 중: 5
11:07:35.518 [pool-1-thread-1] 작업 중: 6
11:07:36.521 [pool-1-thread-1] 작업 중: 7
11:07:37.529 [pool-1-thread-1] 작업 중: 8
11:07:38.538 [pool-1-thread-1] 작업 중: 9
*/
Future.cancel(true): Future 를 취소 상태로 변경 Future.cancel(false): Future 를 취소 상태로 변경. 단 이미 실행 중인 작업을 중단하지는 않는다.
Future - 예외
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public class FutureExceptionMain {
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(1);
log("작업 전달");
Future<Integer> future = es.submit(new ExCallable());
sleep(1000);
try {
log("future.get() 호출 시도, future.state(): " + future.state()); // FAILED
Integer result = future.get();
log("result value = " + result);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ExecutionException e) {
log("e = " + e);
Throwable cause = e.getCause(); // 원본 예외를 받을 수 있다.
log("cause = " + cause);
/*
Future 의 상태가 FAILED 면 ExecutionException 예외를 던진다.
e = java.util.concurrent.ExecutionException: java.lang.IllegalStateException: ex!
cause = java.lang.IllegalStateException: ex!
*/
}
es.close();
}
static class ExCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
log("Callable 실행, 예외 발생");
throw new IllegalStateException("ex!");
}
}
}
작업 컬렉션 처리 invokeAll(), invokeAny()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
/*
invokeAll()
모든 Callable 작업을 제출하고, 모든 작업이 완료될 때까지 기다린다.
invokeAny()
하나의 Callable 작업이 완료될 때까지 기다리고, 가장 먼저 완료된 작업의 결과를 반환한다.
완료되지 않은 나머지 작업은 취소한다.
*/
public class InvokeAnyMain {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(10);
CallableTask task1 = new CallableTask("task1", 1000);
CallableTask task2 = new CallableTask("task2", 2000);
CallableTask task3 = new CallableTask("task3", 3000);
List<CallableTask> tasks = List.of(task1, task2, task3);
/**
invokeAny() 는 한 번에 여러 작업을 제출하고, 가장 먼저 완료된 작업의 결과를 반환한다.
이때 완료되지 않은 나머지 작업은 인터럽트를 통해 취소한다.
*/
Integer value = es.invokeAny(tasks);
log("value = " + value);
es.close();
/*
13:08:26.506 [pool-1-thread-3] task3 실행
13:08:26.506 [pool-1-thread-2] task2 실행
13:08:26.506 [pool-1-thread-1] task1 실행
13:08:27.528 [pool-1-thread-1] task1 완료, return = 1000
13:08:27.530 [ main] value = 1000
13:08:27.530 [pool-1-thread-2] 인터럽트 발생, sleep interrupted
13:08:27.530 [pool-1-thread-3] 인터럽트 발생, sleep interrupted
*/
}
}
public class InvokeAllMain {
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService es = Executors.newFixedThreadPool(10);
CallableTask task1 = new CallableTask("task1", 1000);
CallableTask task2 = new CallableTask("task2", 2000);
CallableTask task3 = new CallableTask("task3", 3000);
List<CallableTask> tasks = List.of(task1, task2, task3);
/** invokeAll(): 한 번에 여러 작업을 제출하고, 모든 작업이 완료될 때 까지 기다린다. */
List<Future<Integer>> futures = es.invokeAll(tasks);
for (Future<Integer> future : futures) {
Integer value = future.get();
log("value = " + value);
}
es.close();
/*
13:10:32.909 [pool-1-thread-3] task3 실행
13:10:32.909 [pool-1-thread-2] task2 실행
13:10:32.909 [pool-1-thread-1] task1 실행
13:10:33.929 [pool-1-thread-1] task1 완료, return = 1000
13:10:34.917 [pool-1-thread-2] task2 완료, return = 2000
13:10:35.916 [pool-1-thread-3] task3 완료, return = 3000
13:10:35.917 [ main] value = 1000
13:10:35.918 [ main] value = 2000
13:10:35.918 [ main] value = 3000
*/
}
}
ExecutorService.shutdown()
- 논 블로킹 메소드( 호출 스레드가 대기하지 않고 바로 다음 코드 호출 가능 )
- 새로운 요청을 거절하고 큐에 남아있는 처리중인 작업을 완료한다.
- 모든 작업을 완료하면 자원을 정리한다.
- 우아하게 종료하는 시간을 정한다.
- ( 보통 shutdown()로 우아한 종료를 하는게 이상적이지만 큐에 남아있는 작업이 너무 많거나 시간이 오래 걸리는 경우 서비스 종료가 늦을 수 있기 때문이다. )
ExecutorService.shutdownNow()
- 논 블로킹 메소드
- 새로운 요청을 거절하고 큐를 비우면서 큐에 있는 작업을 모두 꺼내어 컬랙션으로 반환한다.
- 작업 중인 스레드에 인터럽트 발생
- 작업을 완료하면 자원을 정리한다.
PoolSize
PoolSize Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
public class PoolSizeMainV1 {
public static void main(String[] args) {
ArrayBlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(2);
ThreadPoolExecutor es = new ThreadPoolExecutor(2, 4, 3000, TimeUnit.MILLISECONDS, workQueue);
printState(es);
/*
기본 스레드 개수: 2
최대 스레드 개수: 4 (초과 스레드: 기본 스레드 개수보다 초과해서 만들어진 스레드)
초과 스레드가 생존할 수 있는 대기 시간: 3초
작업 큐 사이즈: 2
*/
es.execute(new RunnableTask("task1"));
printState(es, "task1");
es.execute(new RunnableTask("task2"));
printState(es, "task2");
es.execute(new RunnableTask("task3"));
printState(es, "task3");
es.execute(new RunnableTask("task4"));
printState(es, "task4");
es.execute(new RunnableTask("task5"));
printState(es, "task5");
es.execute(new RunnableTask("task6"));
printState(es, "task6");
try {
es.execute(new RunnableTask("task7"));
} catch (RejectedExecutionException e) {
log("task7 실행 거절 예외 발생: " + e);
}
sleep(3000);
log("== 작업 수행 완료 ==");
printState(es);
sleep(3000);
log("== maximumPoolSize 대기 시간 초과 ==");
printState(es);
es.close();
log("== shutdown 완료 ==");
printState(es);
/*
12:48:12.355 [ main] [poolSize=0, activeCount=0, queuedTasks=0, completedTasks=0]
12:48:12.355 [pool-1-thread-1] task1 시작
12:48:12.370 [ main] task1 -> [pool=1, active=1, queuedTasks=0, completedTasks=0]
12:48:12.370 [ main] task2 -> [pool=2, active=2, queuedTasks=0, completedTasks=0]
12:48:12.370 [pool-1-thread-2] task2 시작
12:48:12.370 [ main] task3 -> [pool=2, active=2, queuedTasks=1, completedTasks=0]
12:48:12.370 [ main] task4 -> [pool=2, active=2, queuedTasks=2, completedTasks=0]
12:48:12.370 [ main] task5 -> [pool=3, active=3, queuedTasks=2, completedTasks=0]
12:48:12.370 [pool-1-thread-3] task5 시작
12:48:12.370 [ main] task6 -> [pool=4, active=4, queuedTasks=2, completedTasks=0]
12:48:12.370 [pool-1-thread-4] task6 시작
12:48:12.370 [ main] task7 실행 거절 예외 발생: java.util.concurrent.RejectedExecutionException: Task thread.executor.RunnableTask@579bb367 rejected from java.util.concurrent.ThreadPoolExecutor@12edcd21[Running, pool size = 4, active threads = 4, queued tasks = 2, completed tasks = 0]
12:48:13.371 [pool-1-thread-1] task1 완료
12:48:13.371 [pool-1-thread-1] task3 시작
12:48:13.386 [pool-1-thread-2] task2 완료
12:48:13.386 [pool-1-thread-4] task6 완료
12:48:13.386 [pool-1-thread-3] task5 완료
12:48:13.386 [pool-1-thread-2] task4 시작
12:48:14.373 [pool-1-thread-1] task3 완료
12:48:14.389 [pool-1-thread-2] task4 완료
12:48:15.384 [ main] == 작업 수행 완료 ==
12:48:15.384 [ main] [poolSize=4, activeCount=0, queuedTasks=0, completedTasks=6]
12:48:18.389 [ main] == maximumPoolSize 대기 시간 초과 ==
12:48:18.389 [ main] [poolSize=2, activeCount=0, queuedTasks=0, completedTasks=6]
12:48:18.389 [ main] == shutdown 완료 ==
12:48:18.389 [ main] [poolSize=0, activeCount=0, queuedTasks=0, completedTasks=6]
*/
}
}
task1 작업 요청: Executor는 스레드 풀에 스레드가 core 사이즈 만큼 있는지 확인 후 스레드 생성
task2 작업 요청: Executor는 스레드 풀에 스레드가 core 사이즈 만큼 있는지 확인 후 스레드 생성
task3 작업 요청: Executor는 스레드 풀에 스레드가 core 사이즈 만큼 있는지 확인, 가득 찼으므로 큐에 작업 보관
task4 작업 요청: Executor는 스레드 풀에 스레드가 core 사이즈 만큼 있는지 확인, 가득 찼으므로 큐에 작업 보관
task5 작업 요청: Executor는 스레드 풀에 스레드가 core 사이즈 만큼 있는지 확인, 가득 찼으므로 큐에 작업 보관하려 했으나 가득 참. 최대 스레드 개수가 4이므로 초과 스레드 생성
task6 작업 요청: Executor는 스레드 풀에 스레드가 core 사이즈 만큼 있는지 확인, 가득 찼으므로 큐에 작업 보관하려 했으나 가득 참. 최대 스레드 개수가 4이므로 초과 스레드 생성
task7 작업 요청: Executor는 스레드 풀에 스레드가 core 사이즈 만큼 있는지 확인, 가득 찼으므로 큐에 작업 보관하려 했으나 가득 참. 최대 스레드 개수가 4이므로 더 이상 생성할 수 없음. RejectedExecutionException 발생
⭐ 정리
- Executor 스레드 풀 관리
- 작업을 요청하면 core 사이즈 만큼 스레드를 만든다.
- core 사이즈를 초과하면 큐에 작업을 넣는다.
- 큐를 초과하면 max 사이즈 만큼 스레드를 만든다. 임시로 사용되는 초과 스레드가 생성된다.
- 큐가 가득차서 큐에 넣을 수도 없다. 초과 스레드가 바로 수행해야 한다.
- max 사이즈를 초과하면 요청을 거절한다. 예외가 발생한다.
- 큐도 가득차고, 풀에 최대 생성 가능한 스레드 수도 가득 찼다. 작업을 받을 수 없다.
Executor 전략 - 고정 풀 전략
ThreadPoolExecutor 를 사용하면 스레드 풀에 사용되는 숫자와 블로킹 큐등 다양한 속성을 조절할 수 있다.
3가지 기본 전략
newSingleThreadPool(): 단일 스레드 풀 전략- 스레드 풀에 기본 스레드 1개만 사용한다.
- 큐 사이즈에 제한이 없다. ( LinkedBlockingQueue )
- 주로 간단히 사용하거나, 테스트 용도로 사용한다.
newFixedThreadPool(nThreads): 고정 스레드 풀 전략- 스레드 풀에 nThreads 만큼의 기본 스레드를 생성한다. 초과 스레드는 생성하지 않는다.
- 큐 사이즈에 제한이 없다. ( LinkedBlockingQueue )
- 스레드 수가 고정되어 있기 때문에 CPU, 메모리 리소스가 어느정도 예측 가능한 안정적인 방식이다.
newCachedThreadPool(): 캐시 스레드 풀 전략- 기본 스레드를 사용하지 않고, 60초 생존 주기를 가진 초과 스레드만 사용한다.
- 초과 스레드의 수도 제한이 없기 때문에 CPU, 메모리 자원만 허용한다면 시스템의 자원을 최대로 사용
- 큐에 작업을 저장하지 않는다. ( SynchronousQueue )
- 대신에 생산자의 요청을 스레드 풀의 소비자 스레드가 직접 받아서 바로 처리한다.
- 매우 빠르고, 유연한 전략: 모든 요청이 대기하지 않고 스레드가 바로바로 처리한다. 따라서 빠른 처리가 가능하다.
- 서버가 감당할 수 있는 임계점을 넘는 순간 시스템이 다운될 수 있다.
- SynchronousQueue
- 특별한 블로킹 큐
- BlockingQueue 인터페이스의 구현체 중 하나
- 내부에 저장 공간이 없음
- 생산자와 소비자를 동기화하는 큐
- 중간에 버퍼를 두지 않는 스레드간 직거래
newFixedThreadPool(nThreads): 고정 스레드 풀 전략 Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
public class PoolSizeMainV2 {
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(2);
// ThreadPoolExecutor es = new ThreadPoolExecutor(2, 2, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<>());
log("pool 생성");
printState(es);
for (int i = 1; i <= 6; i++) {
String taskName = "task" + i;
es.execute(new RunnableTask(taskName));
printState(es, taskName);
}
es.close();
log("== shutdown 완료 ==");
}
/*
13:27:57.870 [ main] pool 생성
13:27:57.886 [ main] [poolSize=0, activeCount=0, queuedTasks=0, completedTasks=0]
13:27:57.902 [pool-1-thread-1] task1 시작
13:27:57.902 [ main] task1 -> [pool=1, active=1, queuedTasks=0, completedTasks=0]
13:27:57.902 [ main] task2 -> [pool=2, active=2, queuedTasks=0, completedTasks=0]
13:27:57.902 [ main] task3 -> [pool=2, active=1, queuedTasks=1, completedTasks=0]
13:27:57.902 [pool-1-thread-2] task2 시작
13:27:57.902 [ main] task4 -> [pool=2, active=2, queuedTasks=2, completedTasks=0]
13:27:57.902 [ main] task5 -> [pool=2, active=2, queuedTasks=3, completedTasks=0]
13:27:57.902 [ main] task6 -> [pool=2, active=2, queuedTasks=4, completedTasks=0]
13:27:58.910 [pool-1-thread-1] task1 완료
13:27:58.911 [pool-1-thread-1] task3 시작
13:27:58.915 [pool-1-thread-2] task2 완료
13:27:58.915 [pool-1-thread-2] task4 시작
13:27:59.923 [pool-1-thread-1] task3 완료
13:27:59.923 [pool-1-thread-2] task4 완료
13:27:59.923 [pool-1-thread-1] task5 시작
13:27:59.923 [pool-1-thread-2] task6 시작
13:28:00.930 [pool-1-thread-2] task6 완료
13:28:00.930 [pool-1-thread-1] task5 완료
13:28:00.930 [ main] == shutdown 완료 ==
*/
}
장점: 스레드 수가 고정되어서 CPU, 메모리 리소스가 어느정도 예측 가능
단점: 점진적인 사용자 확대, 갑작스런 요청 증가 시 큐 사이즈는 무한이므로 대기시간이 늘어난다.
서버 자원은 여유가 있는데, 사용자만 점점 느려지는 문제가 발생
newCachedThreadPool(): 캐시 스레드 풀 전략 Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
public class PoolSizeMainV3 {
public static void main(String[] args) {
ThreadPoolExecutor es
= new ThreadPoolExecutor(0, Integer.MAX_VALUE, 3, TimeUnit.SECONDS, new SynchronousQueue<>());
log("pool 생성");
printState(es);
for (int i = 1; i <= 4; i++) {
String taskName = "task" + i;
es.execute(new RunnableTask(taskName));
printState(es, taskName);
}
sleep(3000);
log("== 작업 수행 완료 ==");
printState(es);
sleep(3000);
log("== maximumPoolSize 대기 시간 초과 ==");
printState(es);
es.close();
log("== shutdown 완료 ==");
printState(es);
}
/*
13:46:02.674 [ main] pool 생성
13:46:02.690 [ main] [poolSize=0, activeCount=0, queuedTasks=0, completedTasks=0]
13:46:02.706 [pool-1-thread-1] task1 시작
13:46:02.721 [ main] task1 -> [pool=1, active=1, queuedTasks=0, completedTasks=0]
13:46:02.721 [ main] task2 -> [pool=2, active=2, queuedTasks=0, completedTasks=0]
13:46:02.721 [ main] task3 -> [pool=3, active=3, queuedTasks=0, completedTasks=0]
13:46:02.721 [pool-1-thread-2] task2 시작
13:46:02.721 [pool-1-thread-3] task3 시작
13:46:02.721 [ main] task4 -> [pool=4, active=4, queuedTasks=0, completedTasks=0]
13:46:02.721 [pool-1-thread-4] task4 시작
13:46:03.722 [pool-1-thread-1] task1 완료
13:46:03.723 [pool-1-thread-3] task3 완료
13:46:03.723 [pool-1-thread-2] task2 완료
13:46:03.724 [pool-1-thread-4] task4 완료
13:46:05.724 [ main] == 작업 수행 완료 ==
13:46:05.724 [ main] [poolSize=4, activeCount=0, queuedTasks=0, completedTasks=4]
13:46:08.733 [ main] == maximumPoolSize 대기 시간 초과 ==
13:46:08.733 [ main] [poolSize=0, activeCount=0, queuedTasks=0, completedTasks=4]
13:46:08.733 [ main] == shutdown 완료 ==
13:46:08.733 [ main] [poolSize=0, activeCount=0, queuedTasks=0, completedTasks=4]
*/
}
모든 작업이 대기하지 않고 작업의 수 만큼 스레드가 생기면서 바로 실행되는 것을 확인
“maximumPoolSize 대기 시간 초과” 로그를 통해 초과 스레드가 대기 시간(설정한 3초)이 지나서 모두 사라진 것을 확인
사용자 정의 풀 전략
- 점진적인 사용자 확대 및 갑작스런 요청 증가에 따른 대응
- 일반: 일반적인 상황에는 CPU, 메모리 자원을 예측할 수 있도록 고정 크기의 스레드로 서비스를 안정적으로 운영한다.
- 긴급: 사용자의 요청이 갑자기 증가하면 긴급하게 스레드를 추가로 투입해서 작업을 빠르게 처리한다.
- 거절: 사용자의 요청이 폭증해서 긴급 대응도 어렵다면 사용자의 요청을 거절한다.
사용자 정의 풀 전략 Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
public class PoolSizeMainV4 {
static final int TASK_SIZE = 1100; // 1. 일반: thread 100
// static final int TASK_SIZE = 1200; // 2. 긴급: thread 200
// static final int TASK_SIZE = 1201; // 3. 거절: thread 200 & 거절 1
// 14:05:48.065 [ main] task1201 -> java.util.concurrent.RejectedExecutionException: Task thread.executor.RunnableTask@368239c8 rejected from java.util.concurrent.ThreadPoolExecutor@12edcd21[Running, pool size = 200, active threads = 200, queued tasks = 1000, completed tasks = 0]
public static void main(String[] args) {
/*
기본 스레드: 100
최대 스레드: 200
초과 스레드 생존 주기: 60초
작업 큐: 1000
*/
ExecutorService es = new ThreadPoolExecutor(100, 200, 60,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000));
printState(es);
long startMs = System.currentTimeMillis();
for (int i = 1; i <= TASK_SIZE; i++) {
String taskName = "task" + i;
try {
es.execute(new RunnableTask(taskName));
printState(es, taskName);
} catch (RejectedExecutionException e) {
log(taskName + " -> " + e);
}
}
es.close();
long endMs = System.currentTimeMillis();
log("time: " + (endMs - startMs));
}
}
- 실무에서 자주 하는 실수: 만약 다음과 같이 설정하면?
1
2
new ThreadPoolExecutor(100, 200, 60, TimeUnit.SECONDS, new
LinkedBlockingQueue());
큐는 절대로 최대 사이즈 만큼 늘어나지 않는다.
기본 스레드 100개만으로 무한대의 작업을 처리해야 하는 문제 발생
Executor 예외 정책
- 소비자가 처리할 수 없을 정도로 생산 요청이 가득 차면 어떻게 할지 를 정해야 한다.
개발자가 인지할 수 있게 로그도 남겨야 하고, 사용자에게 현재 시스템에 문제가 있다고 알리는 것도 필요하다.
- ThreadPoolExecutor 에 작업을 요청할 때, 큐도 가득차고, 초과 스레드도 더는 할당할 수 없다면 작업을 거절한다.
- AbortPolicy: 새로운 작업을 제출할 때 RejectedExecutionException 을 발생시킨다. 기본 정책이다.
- DiscardPolicy: 새로운 작업을 조용히 버린다.
- CallerRunsPolicy: 새로운 작업을 제출한 스레드가 대신해서 직접 작업을 실행한다.
- 사용자 정의( RejectedExecutionHandler ): 개발자가 직접 정의한 거절 정책을 사용할 수 있다.
Reject Code 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class RejectMainV1 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0,
TimeUnit.SECONDS,
new SynchronousQueue<>(), new
ThreadPoolExecutor.AbortPolicy());
executor.submit(new RunnableTask("task1"));
try {
executor.submit(new RunnableTask("task2"));
} catch (RejectedExecutionException e) {
/*
RejectedExecutionException 예외를 잡아서 작업을 포기하거나, 사용자에게 알리거나, 다시 시도하면 된다.
이렇게 예외를 잡아서 필요한 코드를 직접 구현해도 되고, 아니면 다음에 설명한 다른 정책들을 사용해도 된다.
*/
log("요청 초과");
log(e);
}
executor.close();
}
/*
14:19:23.995 [ main] 요청 초과
14:19:23.995 [pool-1-thread-1] task1 시작
14:19:23.996 [ main] java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@b1bc7ed[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@1ddc4ec2[Wrapped task = thread.executor.RunnableTask@133314b]] rejected from java.util.concurrent.ThreadPoolExecutor@5b6f7412[Running, pool size = 1, active threads = 1, queued tasks = 0, completed tasks = 0]
14:19:25.003 [pool-1-thread-1] task1 완료
*/
}
Reject Code 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class RejectMainV2 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0,
TimeUnit.SECONDS,
new SynchronousQueue<>(), new
ThreadPoolExecutor.DiscardPolicy());
executor.submit(new RunnableTask("task1"));
executor.submit(new RunnableTask("task2"));
executor.submit(new RunnableTask("task3"));
executor.close();
}
/*
14:21:50.907 [pool-1-thread-1] task1 시작
14:21:51.921 [pool-1-thread-1] task1 완료
*/
}
Reject Code 3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class RejectMainV3 {
public static void main(String[] args) {
// CallerRunsPolicy
// 스레드 풀에 보관할 큐도 없고, 작업할 스레드가 없을 때, 거절하지 않고 작업을 요청한 스레드에 대신 일을 시키게 한다.
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0,
TimeUnit.SECONDS,
new SynchronousQueue<>(), new
ThreadPoolExecutor.CallerRunsPolicy());
executor.submit(new RunnableTask("task1"));
executor.submit(new RunnableTask("task2"));
executor.submit(new RunnableTask("task3"));
executor.submit(new RunnableTask("task4"));
executor.close();
}
/*
14:25:11.741 [ main] task2 시작
14:25:11.741 [pool-1-thread-1] task1 시작
14:25:12.757 [ main] task2 완료
14:25:12.757 [pool-1-thread-1] task1 완료
14:25:12.757 [ main] task3 시작
14:25:13.772 [ main] task3 완료
14:25:13.772 [pool-1-thread-1] task4 시작
14:25:14.784 [pool-1-thread-1] task4 완료
*/
}
Reject Code 4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
public class RejectMainV4 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(1, 1, 0,
TimeUnit.SECONDS,
new SynchronousQueue<>(), new
MyRejectedExecutionHandler());
executor.submit(new RunnableTask("task1"));
executor.submit(new RunnableTask("task2"));
executor.submit(new RunnableTask("task3"));
executor.close();
/*
14:29:23.471 [ main] [경고] 거절된 누적 작업 수: 1
14:29:23.471 [pool-1-thread-1] task1 시작
14:29:23.471 [ main] [경고] 거절된 누적 작업 수: 2
14:29:24.479 [pool-1-thread-1] task1 완료
*/
}
/*
사용자 정의(RejectedExecutionHandler)
사용자는 RejectedExecutionHandler 인터페이스를 구현하여 자신만의 거절 처리 전략을 정의
*/
static class MyRejectedExecutionHandler implements RejectedExecutionHandler {
static AtomicInteger count = new AtomicInteger(0);
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
int i = count.incrementAndGet();
log("[경고] 거절된 누적 작업 수: " + i);
}
}
}
⭐ 정리
- 고정 스레드 풀 전략: 트래픽이 일정하고, 시스템 안전성이 가장 중요
- 캐시 스레드 풀 전략: 일반적인 성장하는 서비스
- 사용자 정의 풀 전략: 다양한 상황에 대응